Fmea The Easy Way For Testing
FMEA, the easy way for testing
 Image generated by Bing Image Creator to the prompt “A cartoon depicting a flowchart and some people discovering where the thing described fails”
Image generated by Bing Image Creator to the prompt “A cartoon depicting a flowchart and some people discovering where the thing described fails”
Failure Mode Effects Analysis
There is a design review and inspection technique called FMEA, which stands for Failure Mode Effects Analysis. It is frequently introduced in the gumbo of tools and techniques that is Six Sigma literature. It is a technique used to discover, analyze, and prioritize failures in a system, process, or product. The official method is intricate, long, expensive, and detailed.
I use a shorter version of it that goes like this:
- (pre meeting) Diagram the component, flowcharts with numbered labels work well
- Assemble two or more people to analyze the product - developer is a critical participant
- Developer/creator describe how the system in the diagram works
- One part of the diagram at a time, ask what failures could happen at that step
- After the meeting investigate the failures
- For step 0, you really want that person to be the developer
- For failures on step 4, write EVERYTHING down and save the editing/trimming for later.
I have found that the activity above usually takes no more than an hour or so of preparation by the team members and an hour or so of discussion. Meanwhile, the insights and ideas that come of it can be invaluable.
It is not uncommon that during the meeting the team will discover a bug that is intrinsic to the design, something that was not easy to recognize until people consider failure possibilities relative to the by-design behavior.
Tips for the Analysis
It is easy to go off track contemplating failures that this type of analysis doesn’t expose well. The method is not good at exposing any real implementation mistakes - instances where the actual code does not do what the design intended. It is better at exposing problems which are intrinsic to the intended design, places where the design is improperly optimistic, insufficiently guarded against something going wrong even if the code is written to exactly match its intent.
I use the following advice and guidelines when I employ FMEA in this way:
- Assume the code correctly and accurately implements the design as described
- Discuss the system one node at a time
- Use the following failure idea generators
- What if the process aborted right at this point?
- Treat state persistence as a risk point, particularly for abort
- Treat IO as a risk point, particularly if the other side gives an unexpected response or IO failed
- Treat multiple entities interacting in time as a risk point, particularly for race conditions and assumed state
- Consider re-entrancy, what if after abort the process was started again?
- Consider any interaction with users or external agents a critical point You may find other guidelines useful. They sometimes vary based on the system or project. The point is to help with some themes or ideas that help the people in the room think about failure.
Duplicate Issue Detection System Example
Let’s imagine a system designed to detect duplicate failure reports.
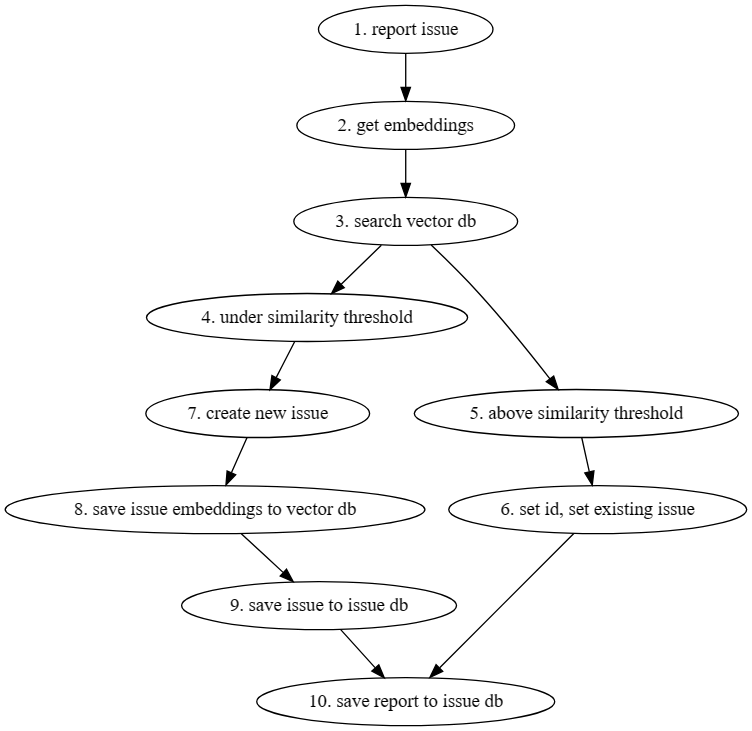
The system behaves as follows:
- the user submits the failure report
- the report is assigned embedding from a trained AI model based on failure text
- a vector database is queried for the top most similar entries to the failure embeddings
- if the top result is below the similarity threshold… proceeds to 7 where a new issue is created
- if the top result is over the similarity threshold…
- assign the id and mark report as existing issue… proceed to 10 where issue report is saved to issue db
- create new issue
- save new issue embeddings to vector db
- save new issue to issue db
- save issue report to issue db
After analysis, the team identifies the following failure possibilities
- at 2, communication with model may fail, model may return invalid embedding results - possibly resulted in persisted bad data later
- at 3, vector database communication may fail, may return invalid results - possibly resulted in persisted bad data later
- at 8, abort AFTER this step means issue embeddings are saved without saving issue or report in issue db (widows and orphans)
- at 9, abort AFTER this step means an issue exists for which the FIRST report has not been persisted (widows and orphans)
- at 10, abort prior to this step means data loss of issue report
The team decides that the most concerning issues are the widows and orphans, and the persisted bad data. Both of those potentially create state that might yield bad behavior later or data that cannot be removed or managed.
FWIW: the above is a real example from a code project of my own, and the bugs from the analsysis are real bugs present in the current version of the project.
Proceeding with Testing
The meeting and discussion on its own is a form of testing. If the meeting happens before the code is written, it is a form of testing James Bach refers to as Prospective Testing (I haven’t located the blog post for this yet.).
Sometimes in the analysis we consider possible failure modes that may or may not actually exist. We might need to look closer. I have had that happen where we had to go to the source code to discover that indeed there was a point where at a critical step a call to an external component was happening without a check for failure on return.
When failures are discovered during the meeting, the response is usually to change the design to handle the failure.
When we test, this now adds a new mode to consider. We might mock up external components, we might create noise and failure on IO channels, we might force abort of sequences (hello, “Terminate Process”) in order to force the failure mode that the design is meant to handle. I find that for every failure mode mentioned, either re-design makes the problem moot (big win!) or we wind up with at least one test to try.
Learning More about FMEA
My favorite book on FMEA is short, inexpensive, and a really fast read, “The Basics of FMEA.” It is 90 pages long, and barely bigger than a coffee cup coaster.
There are a lot of books about FMEA. They are almost all big, thick, and expensive. Most of them spend a lot of time describing how to convince your company to adopt FMEA as a process. Many of them, after a long, exhaustive description of how to do the analysis, calculate measures and metrics and numbers, talk about how to re-implement the process inside specific industries or business cases (production line, help desk, sales channels, distribution channels, etc.). I found them far too much for my needs.
More Test Ideas
The whole point of approaches like above are to make coming up with test ideas and activities easier. I cover lots of easy test analysis ideas in my book.
