Security Testing And Fuzzies And Persistence
There had already been a lot of great security testing

One time I was tasked with driving security testing across a complex V1 release of a product. Each of the groups in the product had already spent a substantial amount of time on their own security testing, but the test manager wanted one more final pass.
The starting problem was an unlocked door
It was a server product, and one of the feature teams allowed client applications to submit requests through a named pipe. Surveying the setup and configuration code for their service, I discovered that there was no autentication or authorization on this named pipe. Instead, the server would process the package in the request first, and after determining what the request was meant to do would then authenticate and check the authorization of the sender of the request to decide if they were allowed to do the operation described in the package.
This meant that data from unauthenticated users was being loaded into the application process space and evaluated. I filed a bug to the product team saying the named pipe was not secured before the data in the pipe was processed. I recommended the product require an ACL be placed on the pipe.
I went to the product team triage. Their response was to reject the bug as “Won’t Fix” for the following reasons:
- The code was shipping in other projects, and those teams had accepted this design. If it was good enough for them, why isn’t it good enough for us?
- The code which evaluated the package had undergone months of rigorous fuzz testing, which had yielded a lot of information leading to security related fixes. The team felt secure that the problem had already been addressed in prior testing.
I felt an obligation to look further into the fuzz testing.
More details about the protocol
The named pipe was for a server component which had shipped in other products before being brought in as part of this larger feature that was part of our V1 release. As such, the protocol for the named pipe and data format were publicly documented on the web. I read that documentation.
The protocol predates some of the client-server communcation protocols that simplified and standardized ways of passing data structures between machines. The server did its own data marshalling. The data structure passed through the named pipe was a block of memory which code on the server would process to construct its own data structure on the server side.
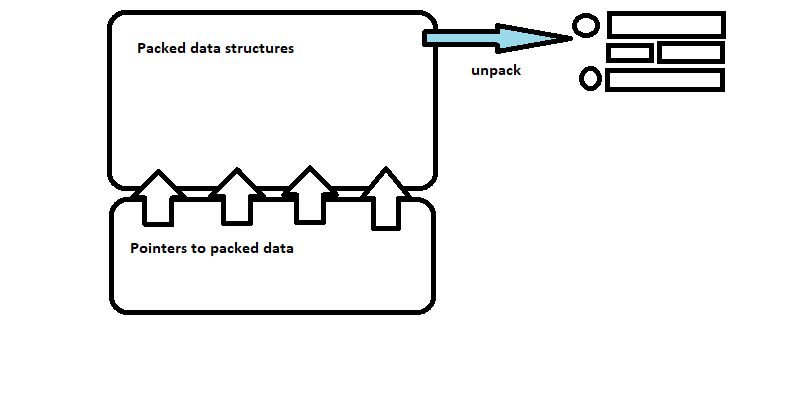
A simplified description of this data structure is:
- a set of pointers to other locations within the data structure
- a set of data blocks which contain the objects comprising the request body
The job of the server side processor was to load the data block from the named pipe into memory, de-reference the pointers to the blocks containing raw memory dumps of the data structures in the payload, and then read those blocks into the memory allocated for the data structures on the server side.
Security risks
The following risks present themselves with this design:
- untrusted client: the client is outside the control of the server, and a principle of security is we always treat something outside our control as if it may be trying to exploit a vulnerability
- pointers under client control: the client dictates the target of the pointers in the payload, which gives it indirect control over where in the computer memory the server is going to go to process data
- payload data under client control: the data is processed under server process privilege, so any exploit possible from processing the data ( especially a buffer overflow) runs a high risk of the client introducing code that may own the entire machine
Fuzz Testing
I decided to examine the fuzz testing code.
I knew the SDET who wrote the fuzz testing tool. He was solid. He had a reputation for finding deep, difficult bugs. His programming skills were top notch. Certainly superior to mine. I had (and still do to this day) a lot of respect for this tester.
The tool was targeting the payload data. The largest risk was that some of the data structures would perhaps contain malicious data that exploited a buffer overflow in the un-packing code, overflowing a buffer over the stack return pointer and jump to malicious code in the payload. The most interesting thing to do was to shake out places where that unpacking code was not checking its data before loading it into memory locations on the stack.
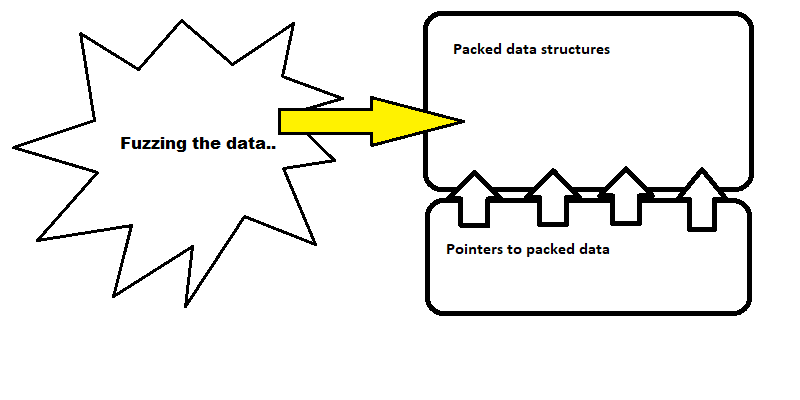
The fuzz testing code targeted these kinds of bugs by randomly corrupting data in the payload. An otherwise valid package would be altered in hundreds of thousands (millions?) of ways. Done in large volume, this type of fuzz testing has been shown to work very well uncovering buffer overflow for data processing and parsing problems.
My assessment of the data structure fuzzing was that it seemed very thorough. The feature team seemed justified in their comfort with the coverage of the data structure unpacking.
But an effective test of data structure unpacking required leaving something else uncovered.
The tool needed something valid to stand on…
If you recall in the description of the data format, there were two main parts to the package, a set of pointers indicating where the packed data structures were in the memory block, and the packed data structures themselves. The fuzz testing tool had targeted the memory blocks which contained the packed data structures. It had left the pointers to the packed data structures intact.
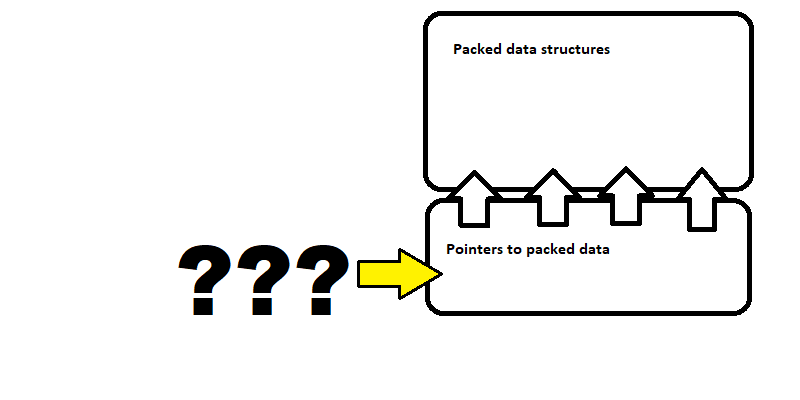
This made sense. Corrupting the data structure package could only be meaningful if the pointers to them were intact and valid. Pointers targeting some other block in memory would render all the fuzzing of the data structures useless and ineffective.
Fuzz testing the pointer section of the package required a separate fuzzer. The tool did not include one.
More really good SDETs
I was driving this effort as an overall project initiative, so I needed more people to help execute on any testing gaps I identified. The feature team had offered me the assistance of another SDET. She also had a good reputation, strong coding skills.
Short story, I showed her what I found. I explained to her I was interested in what would happen were a fuzzer to target the pointers in the data package rather than the packed data structures.
She had the server crashing is less than two days after I showed her the problem.
My takeaways
This experience comes to mind whenever I think of the deep, technical complexities that come up during testing. I also reference it as a reminder of how powerful adding one more set of eyes to a problem is, and how easy it is to feel too comfortable with our prior evaluations. It is also one of my go-to stories about the need for testing persistence when others are skeptical there are any issues to find.