Diary Testing An Ai Based Product
Testing very early versions of an AI bot

I joined the Checkie.ai beta. Checkie.ai is a tool meant to come up with ideas for testing web pages. It is a Chrome extension you can invoke on a given page that will target different bots at the page and produce testing ideas, some suggestions for things to try on the page, some suggestions for possible bugs on the page.
I was curious about the product idea. I know Jason, the author of the tool. I wanted to see how the tool was coming along, but I also needed something to keep my testing muscle in shape, and I really wanted some of that muscle exercised testing something built around AI.
Jason Arbon, the creator of Checkie, knows I am writing this article. He has seen my feedback for most of what I describe here, and more. He told me to feel free to be blunt and harsh. His only ask was I mention the above, and that I publish during daylight hours (Pacific time) so he doesn’t have to wake up to a bunch of people poking him asking if he knows about it.
This article is more like a diary. In some places I describe what I did and what I found. I describe thoughts I have about apps that utilize AI and what it means to test them. I cover a lot of general testing concepts, and what I am thinking while I test. A bunch of this is about the social relationship between tester and the development team, as well as the imagined end user.
Prompt-based applications
One of the ways to use generative AI is as follows
- some tool accepts input on the user’s behalf
- the tool processes the input, breaking it into shorter passages, removing unnecessary material
- the tool selects or constructs canned, templatized prompts that are combined with the processed input
- the LLM produces a response
- the tool processes the response and takes some action, which might mean presenting it in an appropriate form to the user
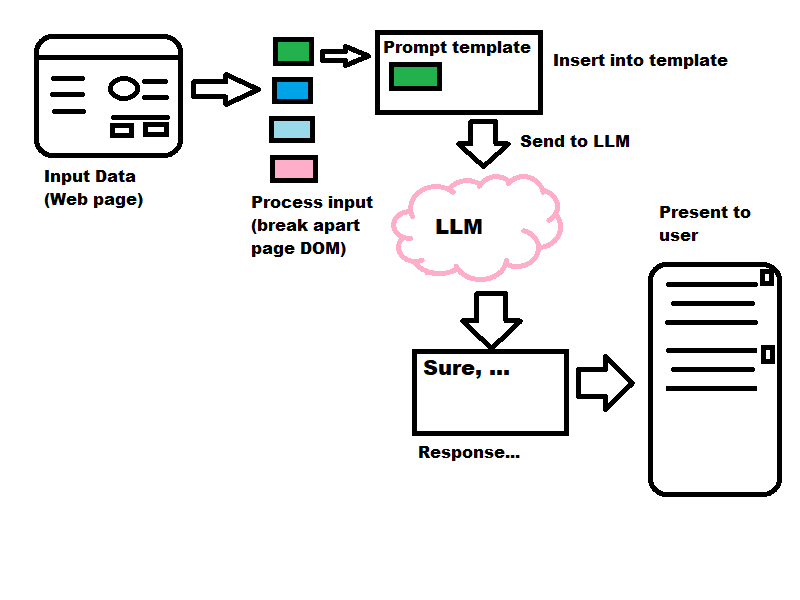
This type of application intends to have a more controlled, more curated experience for the user by taking over the prompt and handling the input going in and out. This is very different from open-ended chat experiences where the user is entirely responsible for the prompt fed to the LLM.
While our typical notion of prompt engineering is a large part of the application functionality, so too, and maybe even more important are the parts that process the input and output to and from the LLM.
Checkie is this type of application.
Early, early application approach
Checkie is barely up and walking. When I first tried to test it, I wasn’t even able to install it. It was written on the Apple platform, and I use Windows. While installing custom extensions on Apple is pretty easy, Windows Chrome doesn’t allow extension installations that did not come from the Android store (unless you are using developer tools in Chromium). I had to wait a week or two until a version was pushed through the Android store.
When something is so early, hitting it with a full battery of tests is almost pointless. The development team (of 1, in this case) might not even know what they want the application to do. You might spend days exploring something only to find that the first bug you reported convinced them they should cut the entire direction of your exploration.
In this case, it is often best to do a quick survey. Look at the surface menus, controls, behaviors. Make note of anything you see going wrong, and move to the next item. If some behavior seems very broken, don’t invest much time investigating details. Instead, tell the development team what you tried, and give them some pointers on where to look next.
Here are a few things I noticed in my survey:
- custom bot settings were not persisting and did not seem to get used
- reports from the built in bots were not persisted anywhere
- clicking outside of Checkie made the screen disappear, along with reports… lost data!
- asking Checkie to run again on the same page produced different reports - I could not get those reports back
- attempts to run Checkie against HTML page I wrote locally spun forever without producing a report
- attempts to use Checkie against online sample testing pages produced similar behavior as against my local pages
- various instances of error messages on the page, corrupted text output, controls that would not dismiss
I sent that list as feedback, as well as the online test sample page I used.
While I did look at the canned bots, I didn’t focus as much on how good the testing feedback was from them. I was hitting public pages (Wikipedia, MSN, Facebook, LinkedIn) and all of those are really busy with a lot going on. Further, all are shipped, in production systems, and if Checkie is supposed to help a tester I would think one would want to do that in a page still in development. This is what led me to my local page, as well as the sample testing page - but both of those caused Checkie to give me nothing. I figured a deeper exploration should wait until I got a new build.
Digging in a little deeper
A day or two later I was offered a newer version. This one fixed the custom prompting.
What follows is an example of how end to end testing causes us to find problems we didn’t anticipate, weren’t looking for, but which prove important to the development team.
It is also an example of a tester being told “You’re doing it wrong,” who persists anyway… and then is thanked later for doing so.
The custom prompt feature allows the user to create their own bot with its own instructions. This made me think of two things:
- As a customer, I might have special business rules important to me that I want all my testers to be alerted to on every page
- I wanted to understand how Checkie uses its prompts, and the custom bot allowed me a way to learn more that the canned bots did not
I wrote a bot called “The Cheese Incident” with the following prompt
If there is no mention of cheese on a page say “No cheese here” If there is mention of cheese on a page say “Checkie found cheese”
I then gave it a web page with the word “cheese” in it, and it said “No cheese here”
I experimented with different instructions. The home page to the website for my blog has all the article titles with all words capitalized. I opened that page, and changed the custom bot prompt to “If there are any phrases on the page that do not use an initial capital followed by lower case, report them.” It reported only the web page title, none of the links inside the page. I tried changing the prompt to “Report all phrases on the page that capitalize every word in the phrase.” Still nothing.
You’re doing it wrong…
I mentioned this to Jason. His response (Jason told me to be open about this stuff) was
Yeah, I think that’s a weird thing to ask ;)… I would expect normal usage to be more like “ are all of the links on this page capitalized”. Or something like that.
I changed it to “Are any of the links on this page capitalizing every word in the link?”, and Checkie’s response was “No.” That was incorrect, because every link on the page was capitalizing every word.
Several hours later when he was able to get to a computer, Jason notifies me. The part of Checkie that was processing the page was not seeing the whole DOM. The custom prompt was only processing the very top of the page.
My tester persistence paid off. It may still be true that the type of prompt I was writing is not really the kind that ought to work well, but there was still a real bug having nothing to do with the prompt causing the problem.
Straddling AI and non-AI
When we test an application that uses AI we should remember than an end-to-end test is going to encompass both the AI component and the code using the AI component. That is what is happening here.
The expectation I had, right or wrong was that a prompt asking Checkie to tell me if any of the links on the page were capitalizing all words in the links would at least say “Yes” if at least one link was doing so.
That it was not could have been a bug in many different parts of the functionality:
- the custom bot instructions might have been ignored
- the page DOM might have been processed incorrectly
- the insertion of the portion of the DOM into the prompt might have gone wrong
- the prompt itself might have been poorly crafted (user error - depending on your opinion)
- the LLM might have had a problem on its side - service outage, dropped data, etc.
- the processing of the LLM response output might have gone wrong
- the UI presentation might have been in error
Even in my naive understanding of how Checkie works, that is seven different ways the same symptom could have presented. It is only in two of those ways that AI is even involved.
How a black box system makes expectations fluid
There are also behaviors that are hard to determine where they would live. Straddling an AI is an example of a black box relationship to ambiguous use case priorities.
If the expectation is that some prompt will do something like find paragraphs using bad grammar, is the per paragraph checking part of the LLM, or is it part of the input processing that breaks up chunks to send to the LLM? If the LLM, then LLM limitations will determine limits on that success. If the input-processing, then the developer might be able to make up for that limitation by breaking the inputs in a way that affords that kind of per-paragraph enumeration.
That difference means that if the team decides things like “check for something at per paragraph granularity” are an important use case, maybe the development team can affect it via input processing. If not, then the bug is left unfixed, and treated as a limitation of the LLM problem.
The reason I raise this point is that “that is just the way the technology works” is used as a reason and often leads a tester to abandon a use case. The truth is frequently more complicated than that, and very often the use case, or at least the undesirable behavior, can be addressed by looking at technology alternatives. As a tester, we should persist our investigation to help the team understand what is really happening.
About input data
The key input data for Checkie is a web page.
On a lot of the example material I have seen around Checkie, much mention is made of things like the Google home page or various other already existing websites.
One of my principles in testing is when the development or marketing team uses a specific piece of data as the demo example, test with something ELSE. All their assumptions about what is safe and good and easy to do are encapsulated in that demo data.
I raise this point because I put most of my attention on pages that I felt would exercise Checkie’s behaviors well enough to understand them, but that led me away from softball, easy to demonstrate cases. This is a cousin of the “You’re using it wrong,” problem. Product managers and developers tend to focus on the cases they know work, and for very good reason. They need to know if the app is doing what it is meant to do, and that is very difficult to do if everything they check is on something outside the normal, easy case. Testing has a different goal, part of which is to understand the behaviors via observation, and that often means introducing behaviors that challenge the assumptions.
As a tester you need to navigate this well. If you revert back to the demonstration, softball cases, you aren’t going to run interesting tests that tell the development team what they need to know. But if everything you do is off on edge conditions the application doesn’t handle well yet, or which the team does not even intend to handle well, then you are likewise not presenting useful information. The challenge is that it takes a while looking at something to recognize where it fits. Some of the pages I tried Checkie did nothing with, but was that from being out on some weird edge case, or did I find something interesting that the development team cared about? My bias is to stay out on the edge and learn as much as I can, stopping only when it is understood.
Remember what we said about your bug making them change their minds?
The custom bot is almost a test hook, left there to allow prompt experiments during development. But it was also left there to see if it was interesting to end users.
The “You’re holding it wrong” back and forth between me and Jason has him pondering the future of the custom bot feature. Whether or not it lives a long and happy custom bot life remains to be seen. It opens up a lot of potential for user confusion, expectations that might be unrealistic.
But meanwhile, I sent some good bugs that would affect other features. So time well spent… but also good to watch your testing investments carefully. I have spent more time writing this article than I spent testing Checkie.
Did we even talk about how well the main functionality works?
In this article, I did not cover the behavior of the main bots much. I focused a lot of my time on the custom bot because I could control it, but also because it immediately seemed to behave wrong, and I wanted to study it more. As I pointed out above, that investigation was useful to the development team (of one…)
I did do some testing of the canned bots against some working web apps, but I am leaving that out of this article. I might cover it in a later article with some updates to the bot prompting behavior. I also want to build up a test app with smaller scoped behaviors to test against where I think the bot responses might be more meaningful.
Diary, end of page
My closing thoughts:
- testing is about exploration and persistence
- the AI is just a part of the application and we have to think about the whole system when we test an AI-based app
- whether something is a bug or not, is important or not, changes in a lot of ways. Our job as tester is to provide the information to understand those changes
- testing a new application which is going to change a lot means being ready to go fast, invest in details carefully, and welcome having all your work thrown away when the product direction changes