Testing Via Hypothesis
Testing from a hypothesis

The cartoon above was generated by Bing Image Creator with the prompt “far side style cartoon depicting scientists testing the hypothesis that giving a cyclist more bicycles will make them go faster”. I kept the weird spelling intact because I felt it made the cartoon funnier.
One time a program manager, James Pierson, told me “I like to think of testing like science experiments. You make a hypothesis and you test it.”
I was inclined to reply with the tester standby comment, “It depends…” but we were working togther on performance, scalability, reliability, and capacity for SharePoint. Science experiments work very well for that kind of testing.
Science you say?
Let’s review the scientific process:
- we pick something we want to understand, we observe its behaviors
- we create a hypothesis that would explain its behaviors, part of the hypothesis are conditions that would have to be true for the hypothesis to be correct
- we create a test procedure to check for if the conditions are true
- the test procedure will keep all parameters the same across every iteration except one which changes as per the hypothesis
- we measure results and compare against the outcome predicted by the hypothesis, and if the outcome is not as expected, the hypothesis is false, if as expected the hypothesis is more likely to be correct
If we framed the hypothesis based on a product requirement, then a false hypothesis indicates a problem, very likely a product bug. If the hypothesis is confirmed, product team stakeholders typically consider that meaning the product met requirements. Testers squirm at that sometimes, because they know more testing may nullify the hypothesis, but we do understand the excitement over positive results.
Sometimes we frame the hypothesis opposite of a product requirement, such as when we are seeking bug repro conditions. In this case, a false hypothesis indicates that the bug is not reproducing for the reasons we were checking, whereas a true hypothesis indicates we probably have the repro.
Product requirements examples: Scalability testing
Let’s imagine you are testing a web-based server product that has a document library feature. The document library supports file upload, download, read, check-out, check-in, document review, and publish (make visible for non-authors in the library). You are interested in the various performance characteristics of the document library functionality. In particular you want to understand how well the product scales.
The product architecture stores the document library data in an SQL database. End user requests are handled by a web-front end application tier which makes requests directly to the SQL server. Multiple web-front servers may access the same SQL database.
This example echoes my years of performance and reliability testing in Microsoft SharePoint. While not an exact account, it is very similar to the kinds of things we would do.
Scalability hypothesis: Does the product capacity scale with more machines?
Customers will want to be able to grow their system to meet end user demand. If they reach maximum system capacity, they will want to expand that capacity somehow. One of the solutions the product offers is to add web-front end servers to handle end user requests to the document library. We want to test how well that works.
We formulate a hypothesis:
“Throughput capacity of a document library workload against the system will grow linearly as web-front end machines are added to the system, without a change in operational latency.”
This hypothesis has a lot to define.
- Throughput capacity: For this problem, we mean Requests Per Second (RPS).
- Document library workload: This will be a mix of document library operations, executed over HTTPS. We will need to choose the percentage of different types of operations, data sizes, user accounts, user privileges.
- Grow linearly as web-front end machines are added: This means that as we go from 1 to 2 to 3 machines and so on, the maximum RPS we can achieve will likewise go up by a factor of X.
- Without a change.. in latency: This is how the increased capacity is checked. We establish the RPS where request latency begins to slow down and establish some point just before it slows down as maximum RPS capacity of the system.
A test procedure to check the web-front end scaling hypothesis for our document library.
We define the procedure that checks our hypothesis.
- Workload: 75% GET on library URI, 15% GET on document URI(s), 5% POST operations against documents evenly spread between save, update, checkout, checkin, publish
- Variable: web-front end configuration being 1, 2, 3, or 4 web-front ends
- Server configuration: SQL database, web front end(s), DNS load-balancer
- Client configuration: Client controller distributing workload requests up to 50 client machines
Procedure per server web-front end configuration:
- Begin workload at 1 RPS, measure latency
- Increase workload by 10 RPS every two minutes, measuring latencies until latency time drops more than 10% below 1RPS baseline
- For hypothesis to be true, the measured maximum RPS values will have to match within 5% the target maximum RPS levels for the configuration NOTE: latency greater than 300 milliseconds for GET operations on library URI will abort the procedure regardless workload
Tables and graphs go well with hypothesis testing. We lay out the changing variables (Web-front end, column 1) and the measurements (baseline latency and maximum RPS, columns 2 and 3) and the expectations (Target RPS, column 4). Web-front end count | Baseline latency at 1 RPS | Maximum RPS | Target RPS
-
1 tbd tbd tbd 2 tbd tbd 2x 1 Max. RPS 3 tbd tbd 3x 1 Max. RPS 4 tbd tbd 4x 1 Max. RPS
We perform the test, and we have results…
We run the tests, take our measurements and fill in the table. Web-front end count | Baseline latency at 1 RPS | Maximum RPS | Target RPS
-
1 50 ms 65 65 2 75 ms 125 2x 1 Max. RPS 3 100 ms 200 3x 1 Max. RPS 4 200 ms 195 4x 1 Max. RPS
Indeed, we did not meet the targets. Maximum RPS falls outside the 5% target starting at 3 WFE, and starts to get worse at 4 WFE. We also notice that baseline latency grows as we add WFEs to the system, which may or may not be related.
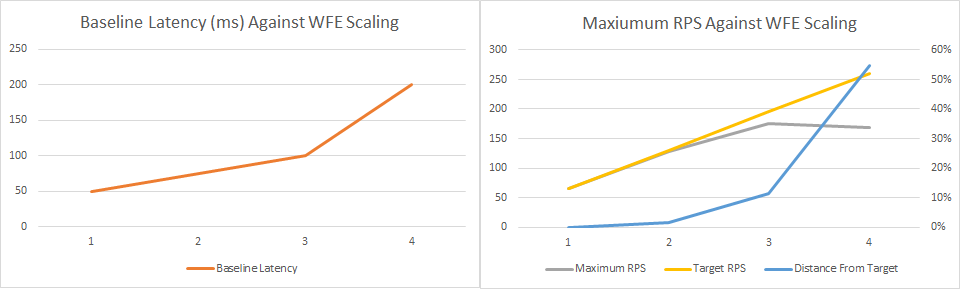
When we examine the results, we find query performance gets worse on the database at 3 WFE, with an increase in the number of table locks. Bug discovered, we move toward a mitigation.
Further testing by creating new hypotheses
Using the approach here, we can continue our testing and exploration by crafting new hypotheses that answer new questions. Consider the following examples all exploring different aspects of scalability on the same product:
“Throughput capacity of a document library workload against the system will decrease as perentage of write operations are increased relative to read operations.”
“Throughput capacity of a document library workload against the system will increase as SQL server memory is increased.”
“Throughput capacity of a document library workload against the system will increase as SQL server number of processor cores are increased.”
“Throughput capacity of a document library workload against the system will scale linearly with number of web-front ends on a single virtual host.”
Testing to reproduce a bug
Sometimes we create a hypothesis to track down the source a problem someone has reported. The approach is similar to testing against product requirements, except in this case we know an outcome we are trying to replicate, and our hypothesis is trying to explain it.
The example story on this one is a short version of a very long, complex, and expensive bug that I encountered when working on the User Profile Service in SharePoint Online.
Example Bug: User renames are breaking user data on the site
Customers on your website allow users to post information to lists. When they do, their name is included along with that information. Ordinarily, if someone’s name is changed on the system directory, their name is also changed everywhere they have added an entry on a list. Some of your customers have said that when their user’s names and login name change (e.g. someone’s last name changes and their login name is changed to match) that their names are not changing for entries they have made on lists on the site. You have been assigned to investigate.
Our hypothesis: Will login name change break user property updates?
You create a hypothesis:
Changing a user’s login identity will cause changes to their last name properties to stop updating to list entries.
The relevant information from this hypothesis:
- Changing a user’s login: This is the experimental variable. The behavior will be controlled against user’s whose login are and are not changed.
- Changes to their last name: This will happen for both the control group (no login change) and the experiment group (login change).
- Stop updating to list entries: This indicates there must have been a list entry for both users prior to the login name change.
Write a test procedure for checking login change hypothesis.
The procedure will go as follows:
- Two user accounts, User1@test.site, last name=One, User2@test.site, lastname=Two
- On list “Test list” create one entry for each user, title=”
entry", confirm user last name for each is "One" and "Two", respectively - Via system directory, change the login id for User2@test.site to User2.Changed@test.site
- Via system directory, change the last name for User1@test.site to “OneChanged” and User2@test.site to “TwoChanged”
- Wait out time period for account changes to propagate
- Check “Test list” for the user last names for “
entry"s - Expected, “User1 entry” last name=”OneChanged”, “User2 entry” last name=”Two”
Note that the expectation is a repro of the bug. The hypothesis states that a simple rename of the userlogin will be sufficient to reproduce the error reported.
Test the hypothesis - a renaming we will go…
You try the procedure as written. You find at the end that “User1 entry” last name==”OneChanged”, as expected, but also that “User2 entry” last name==”TwoChanged”, not expected. You were unable to reproduce the bug using the test procedure. The hypothesis is false.
What does that mean? Does that mean the bug does not exist?
No. We are still getting the customer reports, and we can check their systems to see that user last names are out of sync with their lists. The bug exists. The problem is in the hypothesis. It is insufficient to explain the bug. We do not understand the cause yet. Our experiment has demonstrated there is something different, or something more, than just renaming the user login name to reproduce the bug. It is as if we have a new hypothesis:
Changing a user’s login identity, plus some other thing we don’t know yet, will cause changes to their last name properties to stop updating to list entries. Maybe.
Exlporing around the hypothesis
At this point we consider other possibilities which might insert where (plus some other thing we don’t know yet) exists in the hypothesis. :
- Maybe there is a timing issue
- Maybe there are other events related to the user account synchronization that affect behavior
- Maybe there is something random and we just need to try more
For each of these ideas we would change the test procedure somehow. We could also explore the synchronization code, the list editing code, the user account setting code and see if there are other behaviors which might affect ability to synchronize the user property synchronization.
After some time exploring, you see that in addition to automatically scheduled account data synchronization, you also see that user visits to the site affect account synchronization as well. When the user visits the site, their login identity is written to a list of users on the site. Realizing this, you change the hypothesis and procedure:
Changing a user’s login identity, followed by a site visit from that user before scheduled account sync, will cause changes to their last name properties to stop updating to list entries.
- Two user accounts, User1@test.site, last name=One, User2@test.site, lastname=Two
- On list “Test list” create one entry for each user, title=”
entry", confirm user last name for each is "One" and "Two", respectively - Via system directory, change the login id for User2@test.site to User2.Changed@test.site
- Via system directory, change the last name for User1@test.site to “OneChanged” and User2.Changed@test.site to “TwoChanged”
- (new step)Visit the site page as both User1@test.site and User2.Changed@test.site
- Wait out time period for account changes to propagate
- Check “Test list” for the user last names for “
entry"s - Expected, “User1 entry” last name=”OneChanged”, “User2 entry” last name=”Two”
With the new step 5 inserted, you reproduce the bug. The hypothesis has been demonstrated true in at least one case. You now are much closer to understanding the bug fix.
It’s not always a science experiment, but sometimes it is
We don’t always have a hypothesis in mind, a measurement to make, a procedure to follow. But a lot of the time a hypothesis and procedure to check if you can falsify the hypothesis are a useful way to gather information and build insights.
I describe using hypothesis-based testing in my book Writing Test Plans Made Easy, available on Amazon. The book is mostly about using outlines as a fast way to structure a test plan. Hypothesis based testing is one of the techniques I describe for fleshing out the details.