Flaky Product Design Choice Discovered Via Test Data Analysis
Discovering flake via test analysis without any running code

More of my own cartoons instead of using Bing Image Creator. I am going to try doing this as much as I can partly to keep my own brand on it, partly because I enjoy drawing, and partly because I am starting to feel guilty about the energy costs of image generation.
Testing a product before code exists, in contemplation of the design implications, is something James Bach calls “propspective testing.” I found myself doing that today, unexpectedly, as I contemplated a testing problem the code had not been designed to handle yet.
I was doing data analysis as part of the test specification for a coding project I am working on. That analysis involves drawing a lot of pictures to help me understand the implications of the data structure. One of the problems I started thinking about was loops in the data structure, especially infinite loops.
From that I started thinking about how I wanted to test the infinite looping problem. Do I want to treat it more like an end-to-end black box problem, where I feed larger, complex schema structures to the application and see what it does, or do I want to test at the unit level where I can control the test conditions?
I want to move this problem down to the unit level. This kind of problem end-to-end gets confusing very quickly.
This led to another question about test design. Where does the business logic go for infinite loop detection? At the unit test level, one of the principles of Test Driven Development is that you express how the code should be used in the test, so contemplating this question often forces a re-evaluation of design decisions.
It was during this contemplation that I realized there were performance tradeoffs in the design choices, and the ones which made for the fastest data generation performance also introduced unavoidable flaky conditions. My testing analysis was promoting challenging design choices without obvious answers.
The problem is that the data generation tool supports loops…
In my test data generation tool, there are notions of optional objects and choice objects, both of which rely on a random decision, essentially a coin toss, to determine whether or which object will be used in generation of the final output. For example, a file name might have an optional extension(e.g. “.txt”), or a url might have a set of choices for a top level domain (e.g. “.com”, “.org”, “.gov”, “.edo”).
There is also such thing as a schema reference object, which
identifies a schema object by name, allowing one to build
data objects by re-using previously described schema. For example,
an email name might consist of <username>@<domain>, where
both username and domain have had their schema described already.
One of the problems to worry about are schema structures that
create infinite loops, schema reference objects that eventually
point back to themselves. Reference loops are supported to
allow things like domains, which build up arbitrarily long
sequences something like this domainname => <name>[.<domainname>.
So long as the self-reference is a descendent of an option
or choice of objects there is an escape that can stop the loop.
The problem is when a branch exists from which there is no
escape.
I want to build protection into the app… but we find ourselves trading flake for performance.
I want the tool to detect and avoid infinite loop conditions. There are options:
-
Detect infinite loop as the schema is defined
This requires that when one creates a reference node in a schema definition they also have access to all the previously defined schema objects to allow for inspection of looping conditions at authoring time. This increases integration complexity at schema creation time, as well as a performance cost at schema authoring time that grows as schema definitions graphs get larger. This cost may be deferred to persisting the schema. Another drawback of this approach is it entirely relies on the authoring and persistence mechanism to create “valid” data. The data generation winds up being unable to guard itself in a reliable way without incurring a performance penalty (keep reading, you will see what I mean).
-
Detect infinite loop on call to data generation, but before beginning to generate
Data generation already requires access to a schema defnition store to resolve schema references, so there is no increased integration complexity. The problem will come in an up front cost to evaluate every branch of the schema prior to generating data rather than only having to look at the branches chosen during generation. An advantage of this approach is that infinite loop detection can be tested as an independent problem of data generation.
-
Detect infinite loop during data generation
This option is possibly lower performance, as the need to detect infinite loop only arises in the case where the algorithm decides to evaluate a branch which has a schema reference in it. The problem with this solution is it now introduces a flaky behavior where sometimes a call to the same getRandomExample method will detect an infinite loop and sometimes it will not, even when given the same schema definition.
This is where my test analysis helped out, because understanding the different ways an infinite loop might form in the schema helps us understand the dilemma of choices we face in the design.
The flaky data case - an optional reference to an existing infinite loop pair
This is a case that would behave in a flaky manner if we chose to detect infinite loops during data generation instead of ahead of time.
First, let’s consider an escapable loop. Let’s imagine a case where a self reference to an existing schema object is a descendant of an optional schema object. The fact that the path to the looping reference is optional means there is a chance to escape if during one of the recursions through that path the option comes up NO.
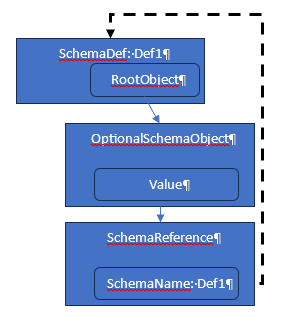
Let’s imagine now a different schema relationship where there is a separate
infinite loop defined between two other schema objects, with no return
back to the original schema. The chance to hit the option that allows escape
is no longer available once we have taken this branch.
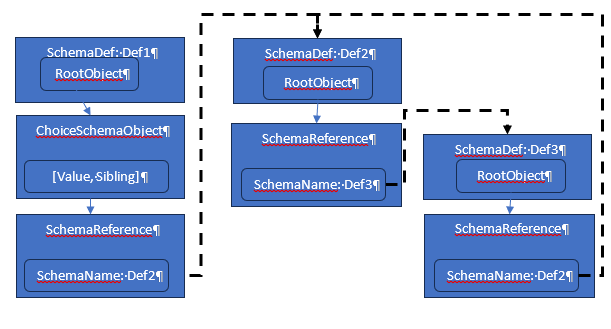
It occured to me after creating the image and writing this passage that the external loop does not need to be two schema items. A single external item looping back to itself would suffice.
This design introduces a flaky condition in the product because the identification of the infinite loop only happens when an inescapable return to a prior schema name is evaluated, but that evaluation only happens if the random decision to take the optional path came up YES. Assuming an even coin flip decision on the option, the schema in our example is going to fail with an infinite loop error 50% of the time. Imagine, though, that instead of being one choice below the schema root the reference was four deep. Assuming an even coin toss on every decision, the probability of hitting the infinite loop is now 0.5 * 0.5 * 0.5 * 0.5, or or 0.06, a failure rate of 6% without changing the application inputs at all.
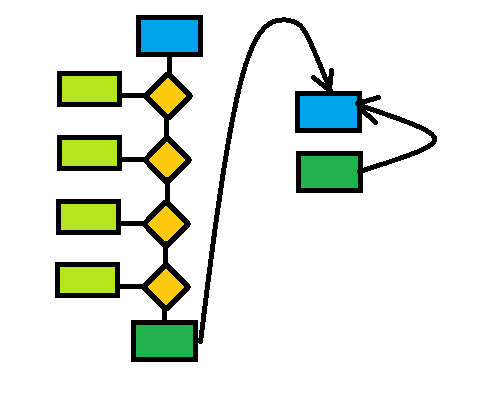
With proper design, error detection rate could be made 100% deterministic under test (see prior article where I describe how I achieve inversion of control via dependency injection of the code that makes decisions). We would write the test such that the mock forces evaluation down the path where the loop begins.
The problem is that even if the test can invoke this failure condition deterministically, a design decision to defer flake detection to when the data is being generated forces us to accept that inconsistent behavior (as per a dice roll) is by design for end users. The end user will sometimes see a failure, and sometimes not, and so long as we commit to this design, there is nothing which will change that.
The reason we are stuck with this behavior is because by design the product is a random data generator. Making new, random examples of data from a schema definition is what it does. Random success cases are expected and acceptable. What the user probably does not want is failure to happen randomly. If a given schema might cause a failure, the user should be notified every time.
If we decide we cannot accept an unpredictable failure event for end users, a flaky product experience, we are going to have to change the design. Either we evaluate schema for loops prior to generating data (e.g. at schema definition time), or we take the performance hit at data generation time to front load the evaluation to make failure happen every time.
Key takeaways about product flake and test analysis impact on design
I started this article thinking I was going to focus on providing examples of product design decisions where product flake is inevitable, the only way around it being to change the design, but in doing that we have to accept something else we might be giving up.
As I wrote more, I took more interest in the prospective exercise of testing prior to completion of product design decisions. I had some working code, but not code sufficient to exercise the conditions described in this article. I knew the data structures, but these were data structure decisions I created before I started coding, so this test analysis likewise could have happened before coding. If this were a formal project some notion of how the product would handle infinite loops in the schema could be expressed in the acceptance tests.
But a simple statement like “DataMaker.genRandomExample will return an error
if a schemaDef object contains an infinite loop.” is insufficient, because
we need to express that requirement as testing data for the acceptance suite, and to
do that we have to ask what infinite loops look like. That is when we do the
propspective testing, and during that testing, we realize the question is more
challenging than the requirement put it, and we probably wind up considering design
changes.
If you are curious, the code is available on my github repository
The code for this project is here: https://github.com/WayneMRoseberry/datatools. I wrote it once already using ASP.NET in C#. I decided to try a version in Node.js because it seemed simpler, smaller, and I wanted to learn how Node.js. That is located in the https://github.com/WayneMRoseberry/datatools/tree/main/datatools.datamakerjs sub directory.