Live Example Of Non Equivalent Testing Data
Whether two things are really part of the same equivalence class can really matter

I wrestled with how much to hold to the stick figure motif when I drew the princess, and decided to commit to the same level as public restroom signs.
Sometimes we believe certain kinds of constructs in our data are equivalent, so we simplify the test data. Sometimes we limit our test analysis to only the kinds of logic that the product code handles. We can very often be wrong about both those assumptions and find bugs later we did not expect because we under-analyzed the problem.
I like to look for ways of describing a test problem that forces us out of that kind of blindness by assumption. I am in the middle of a problem right now where the code for something I am working on is broken and every time I fix something I break one of the other test cases. It is the test data that is keeping me honest.
Boundaries and equivalence in the problem versus in the code
Equivalence classes are sets of conditions which have an identical impact on a given situation. The situation does not change even when the conditions do. Boundaries are the edges of equivalence classes, the points in the condition where moving across the boundary will cause a change.
I am using the term “situation” in a vague way on purpose because I am going to make a distinction between situation as the problem we are trying to solve versus the situation as the implementation that might exist in the code.
If we imagine some application that takes an integer as input, a
typical analysis of the equivalence classes will say the boundaries
are like “MININT, MININT+1, -1,0,1, MAXINT-1, MAXINT”. A naive
analysis, but it is surprising how often that example is given.
But what if the inputs were categorical? What if the number was an ID, and what if there was meaning encoded into the ID assignment? For example, what if the rightmost byte was a bit flag, where each bit indicated some special categorization of the ID? With a range of combinations from 00 to FF, the ID space has been partitioned into at least 256 new buckets.
The problem itself defines the equivalence classes, not the data type. The problem we refer to has eight indepent attributes that apply, and the buckets are derived from a combination of those attributes.
Imagine the developer wrote the code such that rather than looking at every combination of possible bits it examined only single flags, hence just eight categories.
How many equivalence classes are there; 8 or 256? Which is correct? The code, or the problem?
Making this more challenging is that it is possible the developer discovered an elegant shortcut and solving the problem only 8 categories of ID and not the 256 categories that a full combination treatment requires.
But it is also possible that some of the pairwise combinations matter. Let’s say the algorithm is mostly correct, except that the flags 0x00010000 and 0x00000010 combined together as 0x00010010 create a different unique condition which must be handled in a special way. Now, instead of only 8 category partitions, there are 9.
We will not discover that new equivalence class if we let the algorithm as expressed in the code dictate the test analysis. Do we need to do a full coverage of all 256 possible combinations? Not necessarily, as there are pairwise combination strategies smaller than a full expansion of all possible values but that also cover possibilities well. The main point to understand is that there is a difference to how the equivalence partitions might exist in the problem itself versus how the algorithm we chose to implement treats the problem.
When we do test analysis, it helps to look at the problem. Like I did with the code I am working on…
Example: Looping data structures that the code I am writing does not handle right now
I wrote a method to detect infinite loops in the data structures I am working with. The structure describes a data schema via a directed, cyclic graph, where certain nodes can refer to other schema by name, thus creating the possibility of loops.
The method under test is called schemaHasInfiniteLoop().
During test analysis, I came up with several different kinds of looping shapes in the schema, seven of which are diagrammed below, and described after. There are other shapes, but these six are the ones where my code breaks.
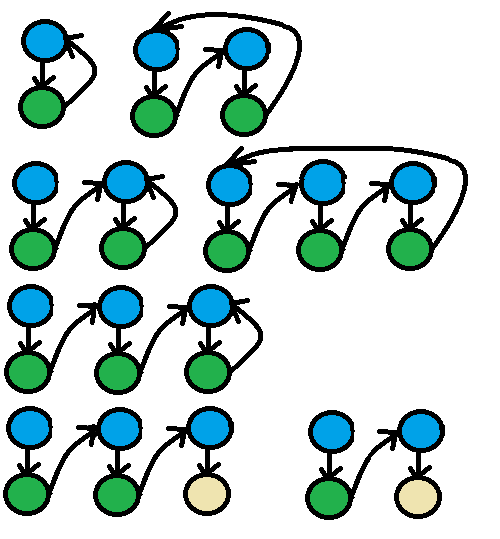
The shapes are:
- Self Reference: a schema object points back to itself
- Second order self reference: a schema object points to another schema object that points back to the first one
- Reference to self referencing schema: a schema object points to another schema with its own self reference
- Third order self reference: a schema object points to another schema object that points to yet another schema object that points back to the first one
- Reference to 2nd order self referencing schema: a schema object points to another schema object that points to yet another schema object that references itself.
- Second order reference to non-loop: a schema object references another schema object that references another schema object that terminates without a reference
- Reference to non-loop: a schema object references another schema object that terminates without a reference
In my original version of this article, there were only six shapes, with just “Second order reference to non-loop” as the only non-looping object. I added one where a first order reference terminates instead of looping, and found it did not break, something that surprised me. I thought that just a reference being there before the terminating object would behave the same was as a second order reference, but I was wrong. More evidence for my point about assumptions that shortcut our equivalence partitions being incorrect.
A day or so later, and I finally figured out how to make the code work with all seven cases shown above. I committed
that to the repo. Then I integrated the loop detection functionality with another method, getRandomExample(), and ran
its unit tests. One of the data structures which does not have an infinite loop failed. I replicated that data structure
in the tests for my infinite loop detection method, and it the bug reproduced there. I had spent so much time
thinking about loop shapes from ReferenceSchemaObjects I didn’t bother to check loops coming in as children all of the other object types.
The mistake here was a matter of being not being thorough. Really, I was being sloppy and forgetful.
From a coding perspective, this is starting to feel like a typical leetcode problem, and I am annoyed I haven’t solved it yet. My motivation is not very high, so I do other things all day, such as write this article, and then get back to it.
What is more interesting to me is how these different cases yield different results, based on the code. From the standpoint of the problem, they are not equivalent, but it is tempting to draw certain equivalence boundaries that would treat them as such. Here are some equivalence temptations:
All schema references are the same as any other schema reference.
Counter: a self-reference and a reference to another schema seem like they introduce different problems.
All non-self schema references are the same as any other non-self schema references.
Counter: it seems the nature of the object referenced introduces problems in the second order of evaluation, so the content of the thing referenced seems to further split the equivalence class.
Depth 1 non-self schema reference is equivalent to depth N of non-self reference.
Counter: it seems possible that generalizing past one jump to a non-self reference might be harder than handling the first jump. Should at least include two levels of non-self reference.
Another way to think of these temptations and counters are some guidelines on coming up with permutations:
- When presented with choices of types of things, take one of each
- Given the possibility of doing something mulitple times, choose 0,1,2,something bigger than 2, and then something huge
- If a target of some equivalence class has another dimension of differences that were meaningful in another equivalence partition, apply the same set of differences in the other equivalence class
- Mix and match more than you believe is necessary
There are other guidelines. The point is to use these kinds of guiding principles to keep us from letting blinders on our imagination limit the test cases.
Force yourself to break apart the equivalence classes based on the problem and testing guidelines
My key takeaway is that testing rules of thumb which push me to go beyond the thoughts I might have had writing the code seem to always work very well exposing mistaken assumptions I had on original coding design. In this example the problem was exposed by more fine grained equivalence classes, and those were driven a generic set of principles I use when considering most test ideas. I make it a point to use them even when I might find them unnecessary.