Exercise Your Tester Mindset By Being A Real User And Comparing Against The Competition
Scenario based tests can also be a way to compare your product to a competing product
I performed a testing session against Kusho.ai, an AI-driven testing tool which automatically creates test cases for REST API based applications. It boasts other features. In this testing session, I focused on creation of cases automatically from an import of Postman test collections, augmentation of those collections through natural language descriptions of test cases, execution of those tests, and then a comparison of doing the equivalent activity in Postman.
I consider this kind of test scenario based testing, simulating a user attempting to solve a problem using the product. I also consider it a competitive comparison test, which can help bring out issues of unmet expectations, but also identify ways the product brings something new and valuable to the customer.
Regarding Kusho.ai and this article
I am not an employee of Kusho.ai. They did not pay me to write this article. I tested Kusho.ai to learn about it, and to have material to write this article. I first heard about it when a co-founder, Abhishek Saikia mentioned it in reply to another article I wrote.
I submitted the test report to Abhishek before writing this article. My reports have been received in a welcoming and polite manner. I showed him this article before sharing it publicly.
For this problem, I needed something real to test.
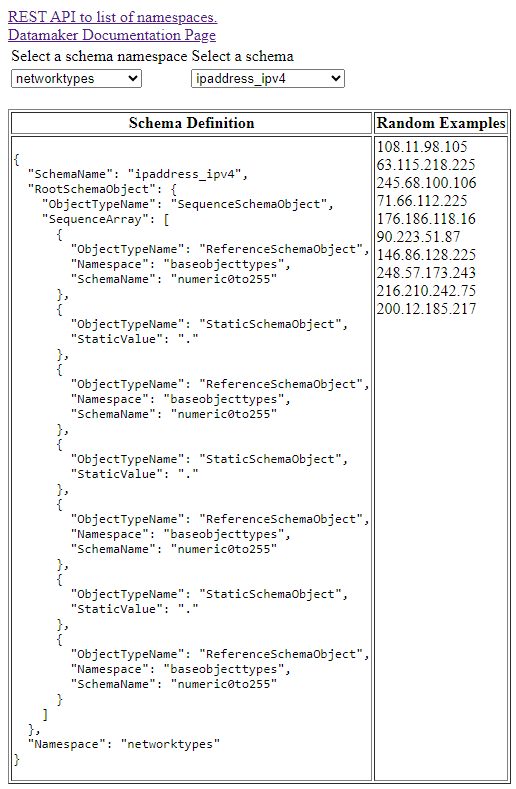
I have created a web-based tool, Datamaker, which allows the creation of random data samples based on a schema. The tool exposes a REST API for viewing available schema, creating new schema, and producing random examples. The tool is currently under development as I write this article, so the need and interest in testing the tool is real. I am not just simulating a target customer, I am really a target customer.
Sometimes it is very difficult to be the target end user, especially with specialized applications. The closer you get the more it pays off.
I prepared a Postman Collection
I created a Postman collection for export to Json for import into Kusho. The time spent creating the collection may have been about 10 minutes. In the collection were five API requests to different URL endpoints:
- GET: https://datamakerjs-f3b6b7d13de0.herokuapp.com/api/namespaces
- GET: http://datamakerjs-f3b6b7d13de0.herokuapp.com/api/schemadefs?namespace=baseobjecttypes
- GET: http://datamakerjs-f3b6b7d13de0.herokuapp.com/api/schemadef?namespace=baseobjecttypes&schemaname=initialalpha1to8charstring
- GET: http://datamakerjs-f3b6b7d13de0.herokuapp.com/api/schemadef/getrandomexample?namespace=baseobjecttypes&schemaname=initialalpha1to8charstring&count=1
- POST: http://datamakerjs-f3b6b7d13de0.herokuapp.com/api/schemadef
The final POST request above creates a schema definition. The body of the request is in the test report that I presented to the founder of Kusho.ai.
Scenario Based Testing
Scenario based testing is easier when you understand the customer problem well. In the case of Kusho.ai, the target end user are people who are trying to test a software product, which is me. I am not a novice with testing, coding, or technology (although I don’t use Postman often), but Kusho promises to save on some of that effort, and that is part of what I am checking for and testing.
As of right now (February 8th, 2024) Abhishek Saikia, a co-founder of Kusho.ai describes the product as in a beta stage. This tempers the flavor of the feedback. Problems are not surprising when a product is beta. Feature gaps are expected, and testing of use case and competitive product comparison provide some perspective on those gaps. If the person testing understands the customer needs well that adds more value to the feedback.
Leading with the bottom line: was it helpful and useful? Yes.
My description of the testing describes several problems I found, some of them severe. Some of them I feel defy some of Kusho’s claims.
The core differentiating capability in Kusho.ai is that it creates new test cases based on descriptions of an API. There is some LLM/AI used for the case creation, although how much is AI and how much is templated case expansion is hard to tell. This automatic case creation is kind of cool, but the product is still in beta, and I think there is more ahead of it than behind it.
Problems aside, I found a bunch of my own product bugs on my web server via the suite Kusho.ai created. Most of these were data handling cases where my server either didn’t handle something at all (oh, a “www” on the front of the url… oops!!!) or was allowing data as inputs I really did not want allowed (blanks and nulls as the names of things in the database? I think not!!!).
My time using Kusho was short and fast, and I think I came out with a half dozen or more things I really needed to fix on my server. That small amount of time was well spent. What I am not sure about is if in its current state that time would continue to be well spent, or if the “automatically create test cases” effect starts to lose steam. Continue reading.
Testing tools do not need to be perfect. They need to be useful, and so long as the money, time and effort spent weigh well against the value of what you learned you are ahead.
I started with the import
The Kusho.ai user interface is very small, which makes it easy to find the main functionality. I chose to create a new test suite. From that I selected to do so from importing a Postman collection, using the one I created earlier.
Sometimes testing with data intentionally designed to exacerbate failure is more effective and efficient. Sometimes testing with real data that comes from a real purpose is more effective and efficient. Scenario based testing tends toward the latter.
Postman also allows creation of test suites by describing the REST API under test. I had done this earlier, but I wanted to investigate their import story.
I was presented with a screen saying I would receive an email when the import processing was complete.
Remember during scenario based testing that your primary purpose is testing, and that trying to get whatever task completed is the vehicle to do that testing. If you focus entirely on completing the scenario you tend to avoid the same problem spots in the product you are there to discover.
As a user of product, when something tells me to wait until a process is complete, I do that. I have had enough things break, data disappear, systems get stuck, hours or effort lost, and other wasting of time that comes of catching a system off-guard and out of its normal state that when I am trying to get something real done, I prefer to tread carefully and follow instructions.
As a tester, that goes out the door. I am going exploring. Not so much maliciously as curiously or impatiently, because I also know that lots of real users are not as cautious as I am, and will impatiently poke around.
When the system says “wait for this thing…” try not waiting.
The first thing I looked at was the status page (indicated after I did the import). It said the import was processing, with 2/5 items processed.
Then I went to look at the test suites. I found two suites there, each one named after one of the requests inside the Postman collection. Inside each collection were several test cases. I had not created these test cases, they were created by Kusho.ai. I read several. I tried running some of them. It was at this point I started noticing issues that I detail in my testing report. Some of the categories of problems:
Usability & UI Anomalies:
The way Kusho.ai names the automatically generated test cases made it difficult to know what the test was doing. There is no way of marking expected results, and sometimes a test would indicate pass when I (as the developer on this project) interpreted as a failure. When the server did return error results (e.g. via HTTP 500 response), Kusho.ai would present nothing in its result pane, not the status code or the content of the response which did have an error message.
Pay attention to confusing UI and incomplete, inconsistent, missing, or misleading information in the UI. Watch for behaviors in the UI that do not seem to match what one might expect. Some of these issues may seem trivial, but they can make a difference between the users begrudgingly tolerating the application and legitimately enjoying it.
LLM and auto-generated content predictability:
Several of the cases were duplicate of each other. User prompt generated cases were unpredictable, sometimes creating what was asked for, sometimes not. I was able to get the LLM driven cases creation to build offensive content, which raises questions about what the requirements are in such a case.
Sometimes it is hard to know what we expect in some application behaviors because the scenario is so novel and new. Raise these types of observations as “what do we want to do here?” questions. It is very possible the team might not have an answer, but it is better to go out ready to observe then be caught by surprise.
Instability and reliability issues:
I never recevied the email indicating the result processing was done. Of the five requests in my collection file, only 3 were presented as test suites with generated cases. Time to indicate done (~18 minutes) seemed very different than the time I experienced creating cases based on user input description of the REST API - which from what I can see took only about 1-2 minutes to generate about 30 or so cases.
Batch processes, data processing, asynchronous operations all have a tendency to certain classes of instability. Sometimes operations do not complete, processes abort, data disappears. Make note of features of this class in the application and pay special attention to them. Small seeming anomalies are often indication of bad underlying problems.
Pay special attention to failure instances. Is there some accounting of the failure? Is there some kind of ID, or pointer to logs or diagnostic information? It may or may not be useful to end users, but it often helps out a lot in support situations when the customer tries to get help with something that failed, and when the product team tries to fix it later.
Comparing to the competition: Time Savings
One of the key claims taken from the Kusho.ai website is as follows:
Generate exhaustive test suites for each API so you save hours of manual effort.
I wanted to check if I was actually saving hours. I decided to try creating the same test cases in Postman that Kusho.ai created for me.
I chose one of the suites, “Datamaker Collection: GET Schemadefs”, of which Kusho.ai created 15 cases (the two others it created 33 and 31). I deemed 5 of these 15 duplicates, so I re-created 10 of them in Postman. I measured my average time to create a new case at 1.2 minutes. Extrapolating out to all 79 cases, I would have spent just short of an hour and a half creating the same cases in Postman that Kusho.ai created without me having to do more than upload the Postman collection file.
There is some truth to the accuracy of the time savings claim with regard to test case creation. The claim of “exhaustive test suites” seemed far from the truth, based on my survey of the tests, but I was not focusing on a comparison of what I would come up with on my own.
Sometimes an informal time and motion study is an easy and inexpensive way to see issues in your own product. It is useful to remember that precision is relative to the problem. Down to a minute or so is fine if comparing on the scale of hours, for example.
A testing activity that yields no bugs, and even provides evidence the product meets goals is also useful. It helps the team understand risk better when they know both what is going well and what may not. It helps open other questions, along the line of “since that seems to be going well, let’s look deeper on…“
Comparing to the competition: Experience
Kusho.ai presents a very simple view of the cases it creates and the responses it gets. I could not see headers, response codes. I could not see exactly what Kusho.ai was doing. It just presented a json blob that indicated what the test sent was meant to be, and then only seemed to present information about the response if it was a success.
I found that in order to use Kusho.ai effectively, I had to run my web server under the debugger. I also switched to Postman, created the same test case there that Kusho.ai created, and then looked at the much more complete, and thorough response. I found several instances where this mattered a great deal. For some responses where Kusho.ai raised no error were failing with different status codes and for different reasons on my server.
As a tester, I have always preferred deep, rich access to lots of information, and as much control over test execution as possible. The automatic test creation features of Kusho.ai are interesting, and I believe worthy of the product developing further, but I need the richer tools more. In this regard, my advice to the product team is that there is a competitive gap between Kusho.ai and tools like Postman they ought to close.
Experiential competitive comparison can be difficult, and much of it is going to be subjective. This is where understanding the end user matters quite a lot. Some of this can wait for feedback from MVP and other releases, but the more you can do to discover these issues even before the end user, the better.
Closing on a scenario based testing session
This was a short testing session. I spent a little over an hour testing, and about the same amount of time writing the testing report.
It is easy to focus on the problem issues, but it is also worth noting when testing discovers evidence of success on product goals. For the use case I presented, a simple Postman collection file, Kusho.ai delivered on saving me what would have been multiple hours of data entry. That is a qualified success, but it is useful for the product team to know how much of their own claims have been observed in realistic scenarios.
Were I to continue this line of testing, I would probably enrich the use case. What would happen if a product team had a larger Postman collection? What if the APIs were richer and more complex? How much does curating and reviewing the suite start to take back that time savings?
It is also important with this kind of testing to be mindful of when in the product lifecycle it happens. Some of the feedback I offered (e.g. not being able to define expected results) was something the product team had already heard and were working on. Sometimes after testing like the above you should talk it over with the team and decide if deeper testing should commence or wait for further changes. You don’t want to repeat the same list of “feature missing here” you gave already if waiting a little longer would give you a chance to see those issues addressed.
Competitive comparisons can take different forms. Sometimes it is a performance test, like the simple and humble time and motion study I delivered here. Sometimes it is more about the relative experience with capabilities the competitor has that will leave a substantial gap in your product.
The website I used for testing against….
It is a project I have on my github site. I built one version of it on ASP .NET, but I wanted to try the same thing in Node.js (I have never written anything in Node before). I copied that into its own repository because deploying to the live site on Heroku was much easier if the repository contained only the Node.js code.
The code on this project is kind of ugly, kind of unorthodox. A lot of that comes from my lack of familiarity with Node.js, Express and JavaScript. I tend to write weird stuff when I haven’t warmed up to a technology yet.