Think Like A Tester But Act Like A Developer And Design For Testability
Why is the application hard to test?

I wrote an article recently about a testing session I ran with ContextQA. One of the key points in the article was that the website I used to do the testing was difficult to automate against. It had testability issues.
In this article I describe a redesign of that application and the impact that had on the automation.
You have to apply some design thinking to make an application more testable.
It is not as if an application is automatically easy to test, and it is not as if one can change the way the code behaves with no thought and instantly have something useful for testing. Testability is similar to other application requirements in that it takes planning and understanding of the user and the problem they are trying to solve.
Can you control it? Can you see it?
There are two important needs for automation, control and observation. The script needs to be able to manipulate and control the system under test. It also needs to see what it is doing, record information about it which can be check, analyze, or use as the basis for decisions and actions within the script. We have problems when the script is unable to control the application, or is unable to use what it can observe for analysis or decision making. In the case of UI our problem is usually being unable to accurately find the objects we want to control and observe because the information available in the UI is not related to the model of the application the automated script is working from.
You want to make the infomration in the UI markup match the model of the application state.
This is sometimes difficult because the language used to design the UI is about layout, visual aesthetics, and channeling behavior between controls and elements in response to input devices like the mouse or the keyboard. There is a gap between the data model used to describe the UI and a model which describes the data and business logic underlying the system coded into the automated script.
What we want to do is bridge that gap by carrying information about the model the tester needs (and by extension the automated script) into the UI markup. There are three main considerations to think about this:
- what is the underlying data or state model?
- what is the purpose of the test?
- what does the UI offer us to present that information?
In the case of my website there were two main problems.
Both of the problems on my website where instances of elements on the page the automated script needed to observe and control, but which were not easy to locate reliably. They were in data that changed as the user selected different options in the UI, and where the layout was imposing logic that was different than the underlying data structures.
Random text output
The first problem was with the random data examples list that updates when the user selects which type of data to show from the schema definition selection list.
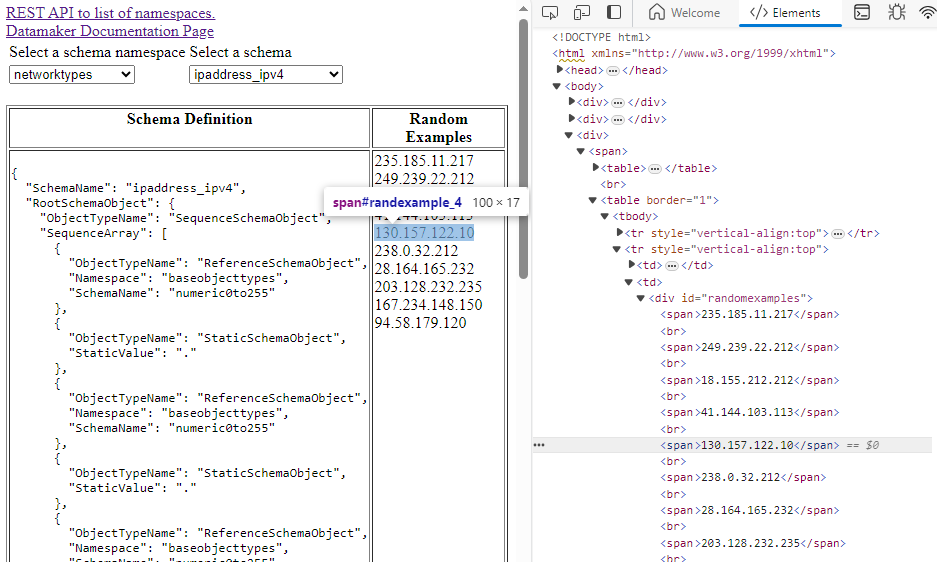
The items are displayed inside a <div> tag, each enclosed in <span> tags.
They have no id on them. In order to find them, one must either try to
locate them based on their text value which will change every time the
user ask for a new set of random values, or based on a pathing strategy
from the parent <div>. This works initially, but if the layout is changed
then the path relationship changes as well. For example, I changed the page
at one point to use a table inside the div with every value inside the second
column of a row. The flat list path strategy constructed by the recorder in
ContextQA could no longer find the element.
Visual schema diagram
The next problem was with the diagram of the schema object.
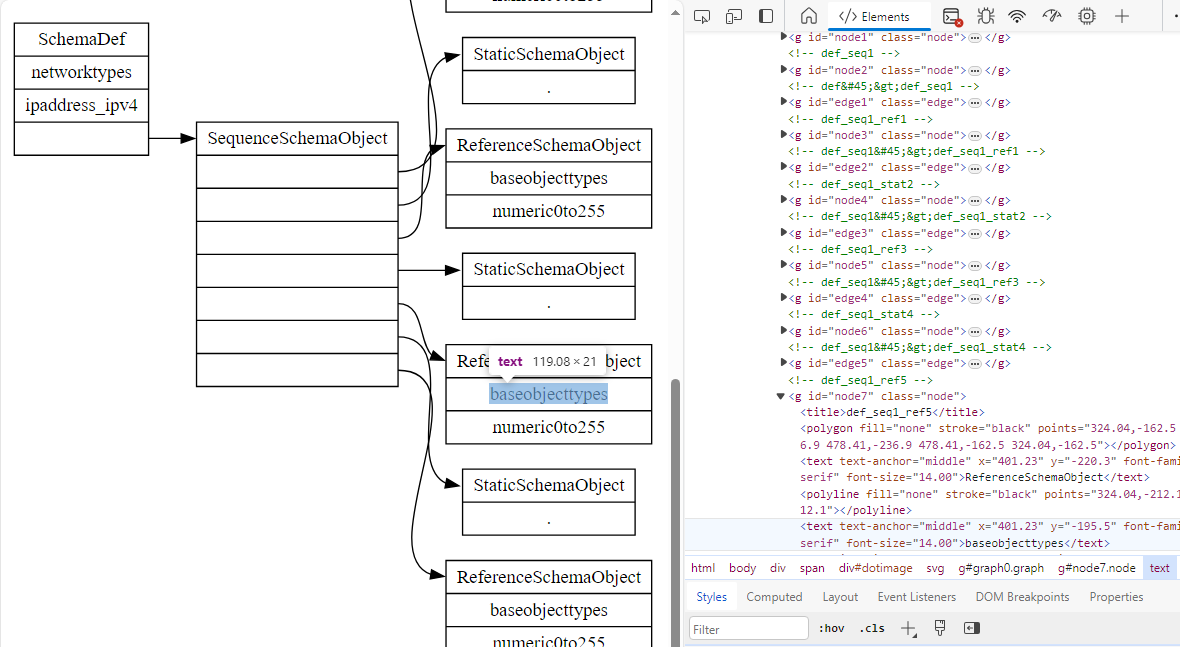
There are artifacts of the fix in the above image in the title elements. This is a version of the page that had been fixed that I “broke” to get the screenshot.
The diagram is produced from a DOT language model of the schema object
that is passed to a library which converts that model to an SVG diagram.
The schema object to DOT language conversion is in the web page backend
code as part of its REST API, while the SVG rendering is produced by the
viz-js library. Each objects are drawn as rectangles in the diagram, their
parent to child relationships represented as lines. The rectanges and lines have
ids, produced by the viz-js library, but they are labelled generically as node
and edge items, with a number to differentiate them. The hierarchical relationship
of the items, though visually obvious as a side effect of geometric placement, is lost
in the actual data. The relationship of each rectangle to which portion of the schema
object it represents is likewise lost.
The imapct on automation strategies is similar, even if the underlying data is more complex. The automation is forced to try to find something in a complicated data layout that comes from something in a similarly complex but different data structure. It has to try to figure out where it is based on geometic and page structure artifacts which may change based on decisions over design aesthetics, or even differences in how the layout engine chooses to re-arrange the graphic elements.
Redesign for testability - how to design the ID tags
Well-assigned ID tags often improve testability of web UI a great deal by providing a more precise mechanism to locate an element on a page without having to worry about its visual representation or the structure of the surrounding HTML elements. To be well-assigned means the ID tag is selected in such a way that it suits the purpose of whatever is using them, which in this case happens to be the automated scripts.
In this case, the element represents specific data structures important to the business logic of the system. One of them is a list of random example output, and the other is a hierarchical definition of schema objects. We want to reliably identify the desired object no matter where it is in the page. The approach for each is similar but different.
ID design for the random example output
The random examples are a simple data structure. There are two attributes that
we need and will encode in the ID. First that each one is a member of a set of random
examples, and second that each one has an ordinal value - its location within that set.
This leads us to an almost obvious format for the ID, RandomExample_<ID#>. Yes, sometimes
the decision is that easy.
The JavaScript for the onChange() event for the selection element controls the
redraw of the random examples and creates the HTML. This is a simple change directly
under application control. The new HTML appears as follows:
<div id="randomexamples">
<span id="randexample_0">235.185.11.217</span><br>
<span id="randexample_1">249.239.22.212</span><br>
<span id="randexample_2">18.155.212.212</span><br>
...
ID Design for schema object diagram
The schema definition is a complicated data structure involving different data
types, multiple valued containers, and hierarchical relationships. To support
testing, we want to be able to locate items based on, 1) the type
of object it is, 2) its relationship to other items in the hierarchy, 3) whether
it is a node or a connection between nodes. We want to encode all of that
in the ID, resulting in two types of IDs to represent, schema nodes
and schema connections. A schema node would be represented as
<nodetype>_<nodetype><childnumber> where the _ represents a parent
child relationship building a path down to an individual element. Connections
between nodes would be represented as <parentid>.<childid>.
The types of item are schemadef, choice, optional, rangealpha, rangenumeric, referenence, sequence, and static. The ID name will assign an abbreviation for each. This creates examples such as the following for a schema definition with a static object in the root, followed by the edge that connects them:
- def_stat1
- def.def_stat1
The following SVG sample from the page (with lots of layout attributes removed) shows how the new objects carry the ID schema in a way that preserces the underlying data schema information independent of the layout information.
<svg>
<g id="graph0">
<polygon></polygon>
<!-- def -->
<g id="def" class="node">
<title>def</title>
<text>SchemaDef</text>
<text>schemaexamples</text>
<text>defaultchoiceschemaexample</text>
<text> </text>
</g>
<!-- def_ch1 -->
<g id="def_ch1">
<title>def_ch1</title>
<text>ChoiceSchemaObject</text>
<text>choice1</text>
<text> </text>
</g>
<g id="def.def_ch1" class="edge">
<title>def:F1->def_ch1:F0</title>
<path></path>
<polygon></polygon>
</g>
<g id="def_ch1_stat2" class="node">
<title>def_ch1_stat2</title>
<text>StaticSchemaObject</text>
<text>val1</text>
</g>
<!-- def_ch1->def_ch1_stat2 -->
<g id="def_ch1.F2.def_ch1_stat2.F0" class="edge">
<title>def_ch1:F2->def_ch1_stat2:F0</title>
<path></path>
<polygon></polygon>
</g>
</g>
</svg>
There are some obvious testing uses for the change in ID. The conventional thing to do is find an item and check its value. One of the nice things about this is we don’t have to fall back to strategies such as looking for innerText, an approach that is fragile if something else on the page has the same text. We also can check value or existence of something independent of its location in the page or in relation to other visual constructs.
Or we can choose to examine those visual construct relationships. If we believe the page layout has locked down, if it is important it stays locked down, then we now have a much more reliable way of saying what an object is, and then we can challenge whether or not it is displayed where it ought to be. We can scan its relationship within the page DOM hierarchy.
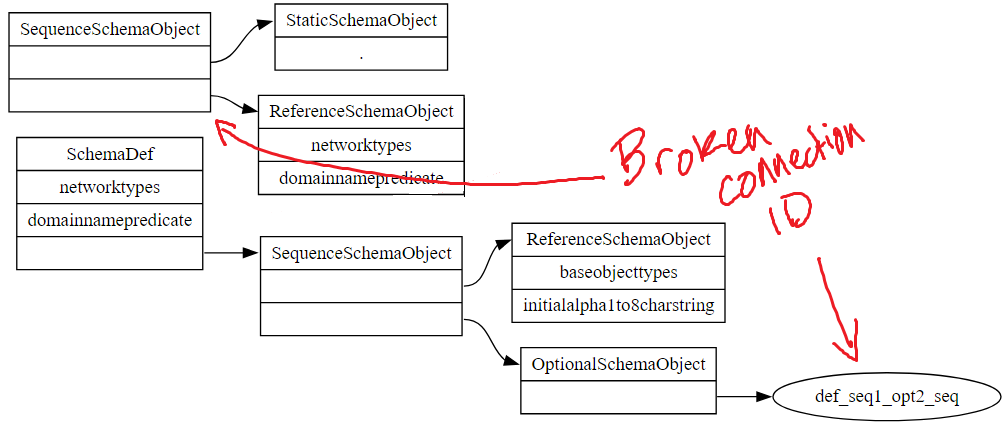
For this application there are other heuristics we can apply as oracles. If we have labelled every object in the schema object SVG, then if we find any instance of something like “Node1” or “Edge1” we can ask why it is there. This is not an uncommon bug in DOT image, as errant labelling and connection specifications tend to create widowed, orphaned and floating objects in the image. What is supposed to be a rectangle will look like an ellipse, or a rectangle that ought to be pointed at by something else is floating alone in the image. We can now check for that condition via the data alone even though the bug manifests visually. Very often when we implement some form of testability we will find that something about the way our application works introduces new opportunities to check for problems that might have been difficult to notice otherwise.
Takeaway from testability design
We can do a much better job testing when we build testability into the application. Sometimes it is a simple change, and sometimes we have to consider a complicated problem. The solutions that work are ones that allow us to deal with models of the product behavior, state, or data in a way that supports the problems we are trying to solve.