Think Like A Tester And Go Beyond The Code
Look beyond the code for the bugs

I found a bug in a project of mine that had been there for a while, but I only discovered it when I added some UI around an API call I hadn’t exposed yet. That made certain tests easier to do, which led me to trying some ideas I hadn’t when I was thinking of the testing problem in isolation.
A data generation tool, and adding new data schemas
The tool is called “Datamaker”, and it generates random data examples based on schema definitions. There is a REST API which allows CRUD operations on schema definitions. I also created a simple UI for the viewing randomly generated example data.
I updated the UI to allow editing of the example schema. I did this because an acquaintance of mine wanted to practice API testing, and I wanted to make it easier for them to see the editing in action with a UI example.

The website has several example data schemas already there. I had created them with the REST API. It stores them in a database on the back end (“database” is not true - the current implementation stores them in a json file that is re-written every time a schema definition is changed or added).
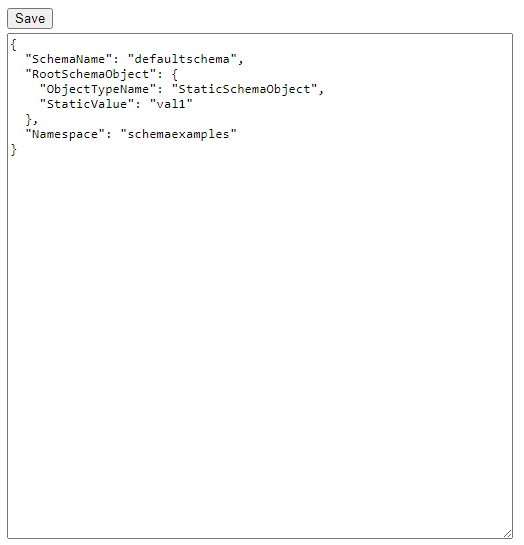
The new editing page is a text area with a “Save” button on it. The schema is presented as Json. It is primitive, and requires the user know the correct json to describe the schema. This is aided somewhat by letting the user pick example schema items and edit them. So long as they keep the data in the same format it should work.
Right?
Foreshadowing. Any story that sets up a presumption of absolute certainty is going to prove that assumption wrong. The same goes for testing.
Simple end to end test cases are really good ways to find coding mistakes
The first test case I tried was as follows:
- open the datamaker website home page
- select “Edit” on the default schema item
- click “Save” on the unchanged schema
- click the “Back” arrow to see the opening screen, refresh, view the list of available schema definitions
That did not seem to present any problems that I could see in the UI. My expectation was that nothing should change. Time for the next test.
- start from the datamaker website home page
- select “Edit” on the default schema item
- change the “SchemaName” value to something else, “defaultschema2”
- click “Save” on the unchanged schema
- click the “Back” arrow to see the opening screen, refresh, view the list of available schema definitions
I expected to see “defaultschema2” added to the list of available schema definitions. It was not. My UI is incomplete, slapped together quickly, and it doesn’t present any status on the save, so there was no error in the UI indicating any problem. I had to debug.
Sometimes very easy tests that tie together multiple pieces are highly effective in catching us where other testing does not.
Testing the failure
I set a breakpoint in the backend code that processes the POST request for the schema definition creation. Stepping through, it hits this code inside a switch statement:
default:
{
throw `invalid SchemaObjectTypeName`;
break;
}
The switch statement was inside the method ` schemaObjectHasInfiniteLoop(schemaProvider, schemaDefName, schemaObject, seenAlreadyArray)`. I already had unit tests around that method, so I stoped the end-to-end test and moved my testing down several layers to the unit level.
Whenever possible, try to move a test to lower levels of abstraction and see if the problem reproduces there where you have more control and fewer variables at play.
I copied the schema definition in the UI into a string and wrote a new unit test.
it('staticschemaobject', function () {
var jsonstring = '{ "SchemaName": "defaultschema", "RootSchemaObject": {"ObjectTypeName": "StaticSchemaObject","StaticValue": "val1"},"Namespace": "schemaexamples"}';
var def = JSON.parse(jsonstring);
var loops = DataMaker.schemaHasInfiniteLoop(new ProviderMock(), "schemaexamples", def);
expect(loops).toEqual(false);})
This test hit the same condition. I had the problem isolated. Now I could figure out the fix. I will describe that in a bit, but after I fixed that problem I ran more end-to-end tests in the UI to find instances of schema that would likewise fail on creation. I found another one, and created a unit test for it as well.
it('non-named static value', function () {
var jsonstring = '{ "SchemaName": "defaultchoiceschemaexample", "RootSchemaObject": { "ObjectTypeName": "ChoiceSchemaObject", "ChoiceArray": [ "choice1", { "ObjectTypeName": "StaticSchemaObject", "StaticValue": "val1" } ] }, "Namespace": "schemaexamples" }';
var def = JSON.parse(jsonstring);
var loops = DataMaker.schemaHasInfiniteLoop(new ProviderMock(), "schemaexamples", def);
expect(loops).toEqual(false);
})
I fixed both problems and re-ran the entire unit test suite. It passed. I ran some end-to-end tests in the UI, and as far as I can tell everything that had been working was still working, and the two cases I fixed were working as well.
Bugs often come in clusters. It usually pays off to look for related, but different bugs similar to one you have just reproduced.
Let’s take a look at the fix, and think about why I missed this bug
The function schemaObjectHasInfiniteLoop has a switch statement in it
that makes different decisions based on the type of the current node in
the schema. I show an altered version of that switch statement below
with the code blocks redacted for readability, except for the two
new cases I added for a blank typeName and the name StaticSchemaObject.
The error case was that if the node were for any of those types of
values it would fall through to the default, which would throw the
error invalid SchemaObjectTypeName.
switch (typeName) {
case 'ReferenceSchemaObject':
{
...
}
case 'SequenceSchemaObject':
{
...
}
case 'ChoiceSchemaObject':
{
...
}
case 'OptionalSchemaObject':
{
...
}
case 'RangeAlphaSchemaObject':
{
...
}
case 'RangeNumericSchemaObject':
{
...
}
// The following two cases are the new items added for the fix
case 'StaticSchemaObject':
{
return false;
}
case '':
{
return false;
}
default:
{
throw `invalid SchemaObjectTypeName`;
break;
}
}
The fix was simple. The bug was simple. The data state that exposed the bug was simple. It was so simple I had no problem creating a unit test to reproduce the failure. It took me longer to edit out the end of line feeds in the sample data than it did making the test code. Why did I miss this bug until after I made changes to the UI to allow editing of the schema?
That pesky developer mindset
The code was built in the following order over a disjointed timespan. Days? Weeks? I do not remember, but I do know the order.
- implemented addSchemaDef and implemented the POST schemadef REST API
- tested different sorts of schema objects against the addSchemaDef API, including the examples on the website
The point about the testing is important. I have unit tests directly against the core classes and functions that cover all sorts of types of schema and node types. It is pretty thorough. Once the REST API was running, I used it to create examples of each of the types of data, plus some more complex scenarios, such as composite schema that build URLs from lower level schema constructs. Those examples reside on the website, persisted in the backend storage.
There was also a primitive UI, but it did not have editing exposed. To do edits, one had to use something like Postman to submit a POST operation to the REST API.
- implemented ‘schemaObjectHasInfiniteLoop’ and wrote tests to cover different looping constructs
- for performance reasons, placed the call to ‘schemaObjectHasInfiniteLoop’ inside the REST API, but not inside the addSchemaDef API
Detecting loops, or other forms of invalid schema, became a concern once I opened up the REST API for edit submissions. I implemented a method to detect infinite loops or other invalid states. The same routine that creates a schema item also instantiates it from persisted storage, so speed was a consideration. I decided to move valid schema detection out of creation/instantiation and into the REST API code so that the hit would only happen once when the schema was either created or edited. I decided anybody creating schema programmatically straight from the javascript classes could do the same check.
The code behind the REST API POST request is below:
router.post('/schemadef', function (req, res) {
console.log('POST schemadef');
console.log(` schemaDef:${JSON.parse(JSON.stringify(req.body))}`);
var response = {};
try {
const schemaDef = JSON.parse(JSON.stringify(req.body));
if (typeof schemaDef.Namespace != 'string' || typeof schemaDef.SchemaName != 'string') {
throw CommonSchema.MUSTBESTRING;
}
if (schemaDef.Namespace == ' ' || schemaDef.Namespace == '' || schemaDef.SchemaName == ' ' || schemaDef.SchemaName == '') {
throw CommonSchema.MUSTNOTBEWHITESPACEOREMPTY;
}
// the call is placed here, inside the REST API to push the call to check for
// loops is expensive, so keeping it out of the main schema creation code
if (Datamaker.schemaHasInfiniteLoop(provider, schemaDef.Namespace, schemaDef, [])) {
throw `schema has infinite loop`;
}
provider.addSchemaDef(schemaDef);
var newlymadeschema = provider.getSchemaDef(schemaDef.Namespace, schemaDef.SchemaName);
response["SchemaDef"] = newlymadeschema;
response["SchemaDefUrl"] = buildSchemaDefUrl(getBaseHostURL(req), newlymadeschema.Namespace, newlymadeschema.SchemaName);
}
catch (err)
{
if (exceptionIsKnownInvalidSchemaConditions(err)) {
res.status(400);
response["error"] = `invalid schema: ${err}`;
console.log(`error:${err}`);
}
else {
console.log(`error:${err}`);
throw err;
}
}
Application functionality is built up over time, and sometimes testing we did earlier is relevant to code we add later even when we do not believe it is.
This is where I cut my testing short without realizing it. As per the switch statement around the bug fix, the algorithm for detecting infinite loops was looking for constructs that branches in the schema structure, which were ‘ReferenceSchemaObject’, ‘SequenceSchemaObject’, ‘ChoiceSchemaObject’, and ‘OptionalSchemaObject’. It also included cases for ‘RangeAlphaSchemaObject’, and ‘RangeNumericSchemaObject’, which are not branching constructs. When I was thinking of tests for this method, I was only thinking about anything that might possibly create a loop, and the resulting unit tests covered loop shapes of varying type, depth, and complexity. All the other types of nodes were treated, in my mind, as equivalency classes as they were instances of nodes that terminated, and so long as I had one I was covering the equivalence class.
I was wrong about that, and it was a boneheaded way to be wrong. A switch statement is very explicit, and very obvious about what it handles. But I was wrong anyway. As it turned out, every type of node mattered uniquely in the logic as written, and testing anything less than all types of nodes was insufficient coverage of the testing problem.
Quick thing to point out: even with this gap, that function had 100% code coverage. The bug was in two missing code blocks. Code coverage never tells you about missing code blocks.
So, that end to end test
It is pretty easy to piece together the story from here. I had data on the website created by testing of the REST API prior to the check for infinite loops were added to the POST request handling method. My testing of the changes focused only on schema definitions that created branching and looping structures, so certain types of nodes that I had covered in previous testing had been skipped. I didn’t bother to do any more testing until I added a UI to edit schema items.
And it was when going through this old data that I found my changes had caused a code regression.
It would have been very easy to catch the same bug in a unit test when I wrote the loop detection code. The two cases are above in this article. They are short and simple. The problem was not how hard it was to test. The problem was I was not thinking through the problem deeply enough. I let my awareness of what was in the code blind me to thinking more broadly. I was using what I knew about how the code worked serve as a filter against other possibilities because I thought they were not relevant.
End to end tests, and tests selected in ways that seem only tangentially related to a problem but which tie all the same parts of the code together can be very effective at showing us where we have missed something when our attention was focused narrowly.
Thinking about testing beyond the code
I feel like I was being sloppy, and the story is embarassing. My only consolation is that the project was more personal experimentation than it was something serious. Another consolation is embarassing mistakes like this one serve as good testing stories.
The key lesson I want to describe is how a mind focused narrowly on how someone understands the code behavior can be a filter, a blinder, to critical testing that would find bugs in that same code. Contributing conditions can be things like testing that is harder to do (e.g. as in this case where I lacked UI to easily knock off fast tests). To remove these blinders, you should take steps to force yourself outside the code. In this example, when I finally did the testing, I stopped thinking about what was or was not relevant and just used a pile of data I already had available. I stopped assuming what should or should not be relevant and chose tasks that tried to get all the moving parts engaged. My mistake assumptions were exposed quickly once I started down that path.