Flake Is About Control
Flaky behavior is about control
 Sometimes trying to control a system while testing it
feels like trying to drive a car from the back seat. That
long distance, awkward loss of control is why we see
flake when we test a product.
Sometimes trying to control a system while testing it
feels like trying to drive a car from the back seat. That
long distance, awkward loss of control is why we see
flake when we test a product.
Throughout this document I use the term “test procedure” to refer to any set of steps or actions taken during the execution of a test, including establishing preconditions, manipulating test conditions, manipulating the system, or observing the system. I use this term because it is important we remember that “flake” happens for any kind of testing. There is too much attention paid to whether we are using automated scripts, certain tools, or if a person is executing the test themselves interactively with the product. None of these matter, because the same definition applies, the same principles of control apply.
I also avoid as much as I can the phrase “flaky tests.” I slip here and there because sometimes attention is directed at the output of a specific piece of testing collateral, especially an automated check, that may produce inconsistent results at whic point people say “flaky test.” My problem with that label is it suggests a foregone conclusion that something is wrong with the test procedure, and that the result, just for being different on multiple executions, is a false positive, that it does not suggest any real bug in the product and only in the test procedure itself. The truth is that a great deal of “flake” comes from the product itself. All you need to do is spend some time reviewing customer bug reports, answer support calls, or perhaps use the product yourself to recognize how often we experience problems that come and go, seemingly intermittently with no perceivable reason.
So, flake is what, exactly?
My definition of flaky results is as follows:
Flake: when you get different results from executing a test procedure multiple times without changing the test conditions.
That sounds simple, but there is a lot of complexity wrapped up in that statement.
Without Changing the Test Conditions
Is it possible to actually have different results from the same test conditions? Casual experience might suggest yes, but when we consider the way we understand the universe (at the macro level, this is not quantum physics), then under the same conditions we must get the same outcomes every time.
It is not that the conditions are unchanged. What happened is something changed which we do not understand or control. But it is important that we understand the difference between conditions in general and test conditions. Flake is defined relative to test conditions.
Conditions versus Test Condtions
Let’s define two terms:
Conditions: variables that when changed also change the state of a system.
Test Conditions: variables that a test procedure will either observe or control.
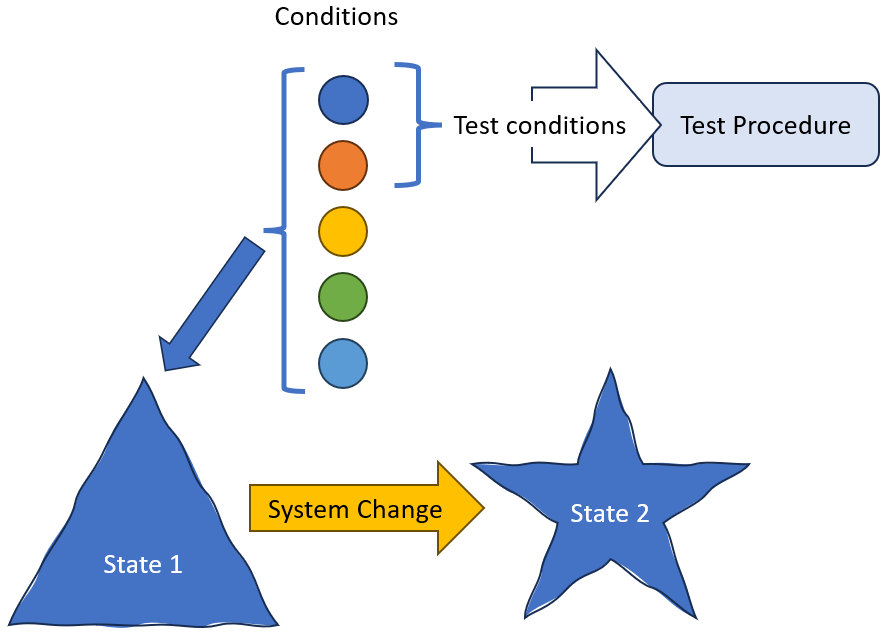
This separation between all conditions that affect the system state and test conditions is critical to understanding why we observe flake. When all conditions are under control of the test procedure, then everything that affects the system state is a test condition. When everything that affects the system state is a test condition then we can eliminate flake because the test procedure is able to establish a deterministic relationship between changes it makes to test conditions and system state or behavior.
It is when there are conditions that change which are not part of the test conditions, not something the test procedure controls, that we experience flake.
An example
A website has a scheduled timer job that executes every X minutes to look for data to purge from the system. The site exposes a REST API with a set of CRUD operations for objects that site handles.
A set of automated checks use the REST API to check product functionality. The automated checks do not have access to the server, its settings, or its diagnostic output. All the checks are able to do is execute against the REST API.
The state of the timer job (idle, executing, down, and what action it is executing) is unavailable to the automatced checks. This set of states are conditions of the system under test, but not test conditions.
The inputs to the REST API, and the website response to those inputs are under control of the automated checks. These are test conditions.
Everything behind the REST API is a black box.
Time(r) for a flaky example
Let’s imagine there exists a race condition bug where adding a certain type of object via the REST API will get purged if the timer job and the addition of the object line up at precisely the correct time. Maybe some piece of data on the object keeps it from being purged, and maybe the initialization of that data is happening after the timer job checks.
If we run the check which adds this object, sometimes it is going to write the object during a window where the object is purged by the timer job. If the procedure then checks if the object is in the store, it will see it is missing, and reports a failed expectation.
If we run the check again, chances are it will not happen.
A condition within the product changed, but it was not a test condition because the test is not able to either observe nor control that condition. This manifests as a flaky result.
We will get back to this example later.
The inherent flake of this system test
The flaky problem we hit arises as a side effect of the black box nature of our system state. So long as the conditions which affect the system behavior are not included in the test conditions there will be potential for flake. We don’t plan the flake, it arises when the system is affected by conditions we do not anticipate.
The flake can be frustrating. But we also need to learn how to make it happen. The system is a black box to everyone, not just test procedures, which means that the same conditions the tests cannot control will almost always be the same for customers and end users. Usually more restricting. Whether or not a certain bug always occurs when a certain condition is true does not make that bug feel consistent and reliable to the customer when they are unable to control or observe the condition. For all practical purposes, from the sake of experience with the black box, the bug is flake.
From testing perspective, we need two fronts of attack on this problem. We need to gain control of more test conditions on the one hand to get precise target of bugs we expect to find, and we need to continue to surrender control to discover the bugs we did not expect.
Conditions and Control
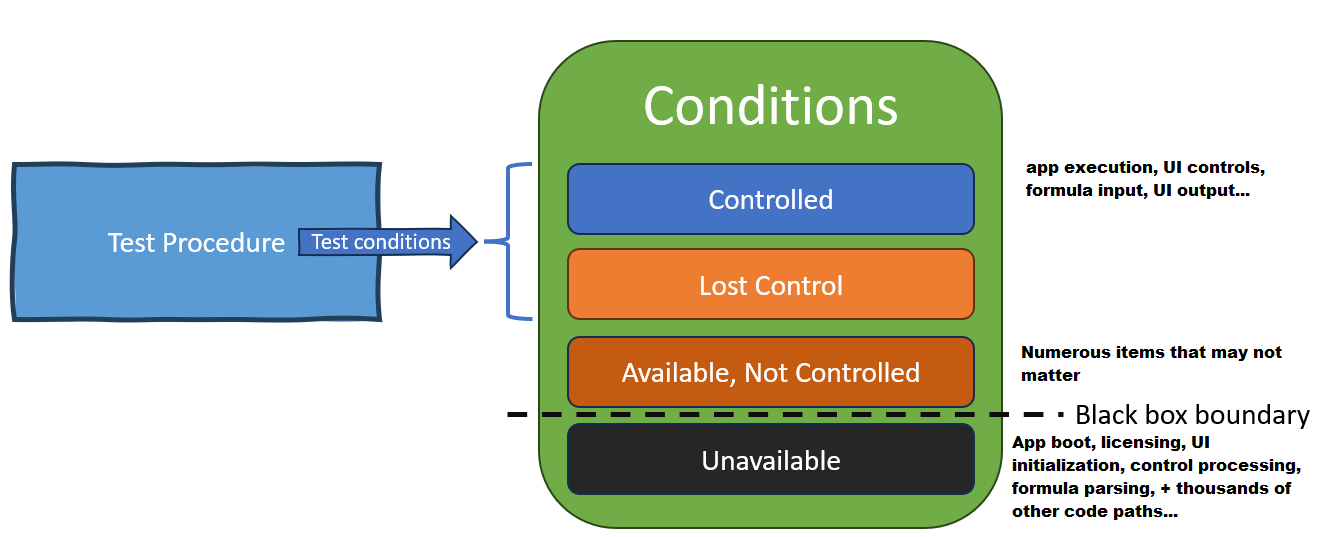
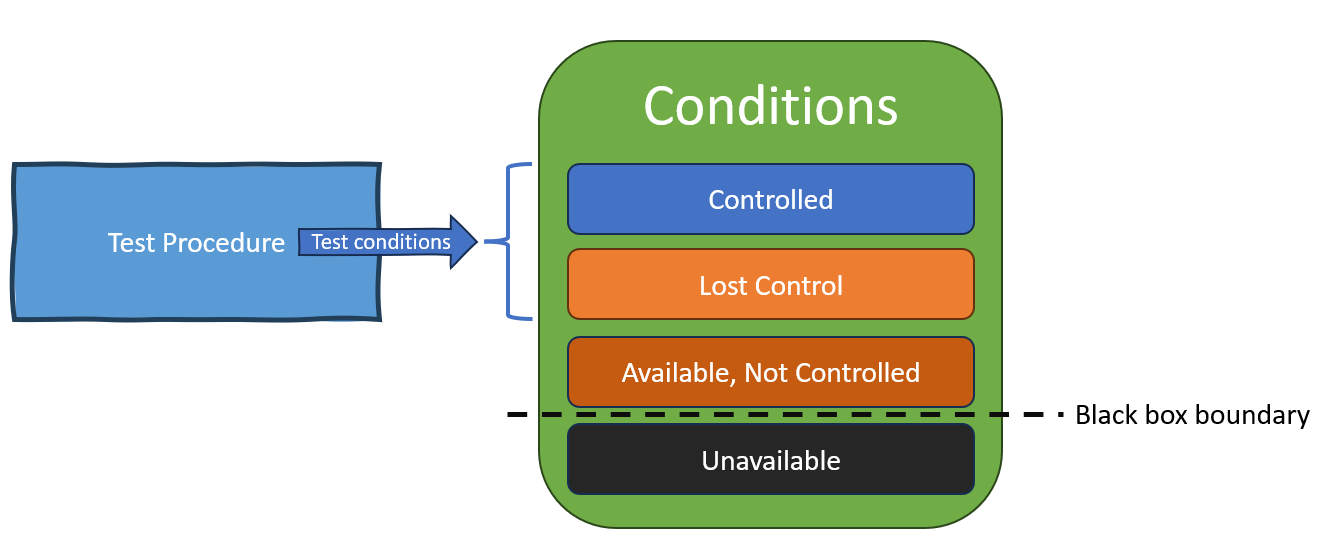 A test procedure is related to conditions of the following classes
A test procedure is related to conditions of the following classes
- Conditions it controls
- Conditions it tries to, but loses control over
- Conditions available to control that it does not control
- Conditions unavailable for control
1 and 2 from the list above are test conditions because the test procedure attempts to observe or control them. Conditions in 3 are not test conditions because even though those condtions are available to control the test procedure does not control them. Conditions in 4 generally reside inside the black box of the system under test and are not test condtions because the the procedure is unable to control them.
The system produces flake when one of the conditions not under the test procedure control (classes 2-4 above) changes and produces a different result in the system, even though none of the condtions under test procedure control have changed.
Let’s make this real… what about the end user?
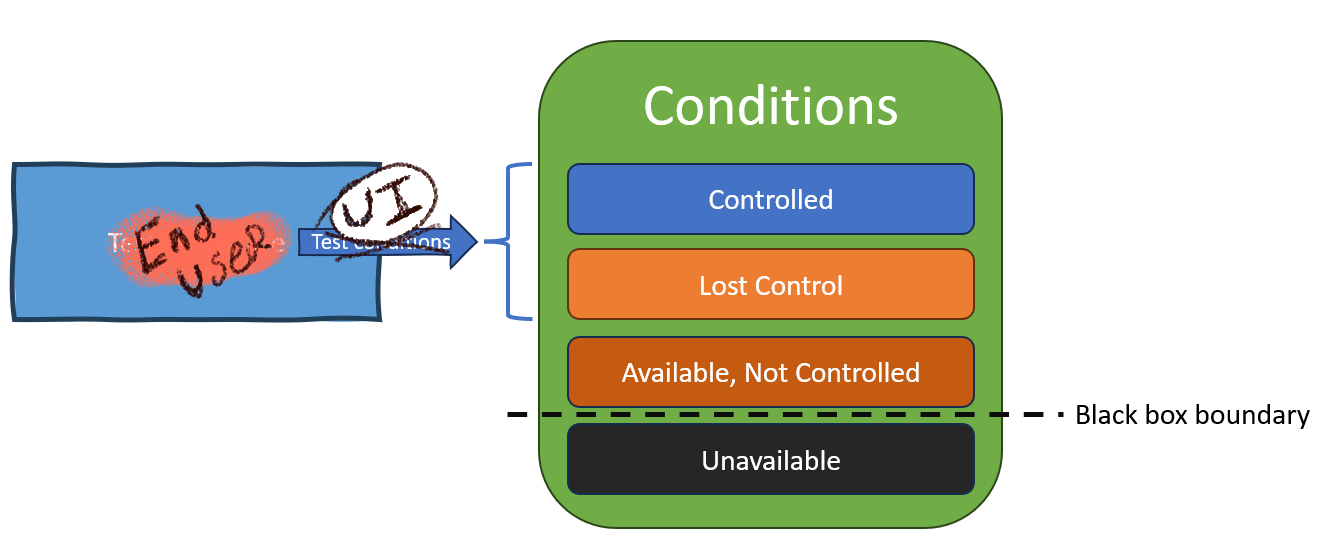
A clever reflection on this notion of conditions we can control, cannot control, or lose control of will remind us of how end users experience the same relationship to the product as we see during a test procedure. The User Interface defines which conditions end users may affect, and everything else is outside their control.
Just like our test procedure, the end user will encounter flake when changes they made to conditions they control produce different results from the application as conditions they do not control change.
We ship flake all the time. Our end users live with it on a daily basis. Very often that flake results in something which upsets, sometimes harms the end user. Our desire ought to be to prevent the end user from experiencing flake that upsets them or causes them harm.
The same happens to the owners and operators of the business. When conditions in a data center or behind some application cause a system state change that is bad - maybe an outage, maybe exposing private data to a malicious third party, maybe running up service costs - the owners and operators of the system become the end user. We live with flake that threatens the business all the time in our live systems. Our desire ought to be to prevent such flake from deploying to production.
Different ways of establishing and managing control
Correcting Lost Control: This is almost always about bugs or bad design choice in the testing code or testing framework. When people offer advice about better coding patterns, better ways to use testing libraries and SUT artifacts, they are addressing lost control of test conditions. Vendors target lost control by offering tools and solutions which promise to either give the script more control, or to mitigate some of the lost control behaviors with programmatic accomodations via “self-healing.”
Gain Control of Available Conditions: This is usually about testing code or framework not taking advantage of control points available to them. Vendors also target this class of control by offering solutions and tools which make certain kinds of conditions easier to roll into a test script or framework.
Gain Control by Moving Conditions from Unavailable to Available: This means either changing the system itself so that conditions can be controlled and/or observed by the test procedure, or alter the test procedure so that it is executed at a point where those conditions are available. This includes providing control points and test hooks for end to end testing, but probably the most powerful and effective way of creating test control is done via refactoring during unit testing.
Surrender Control by Compensation for Unavailable Conditions: Sometimes we attempt to compensate for loss of control by using probability to increase the probability of behavior change in the conditions unavailable to the test procedure. The most common technique is simple repetition. If a failure happens once, run the test again to try for a change in conditions and thus system state. If hunting a particular failure, or looking for unexpected failures, run the same procedure many times, rolling the dice in favor of the right condition eventually changing to produce the target system state. Sometimes, we don’t even need repetition. Running the system end to end, with all system variables interacting, especially utilizing complex operations and user scenarios tends to affect conditions inside the system in a ways that our more directed, controlling testing does not anticipate. This is the key reason why end to end system testing finds bugs that unit testing does not.
Gaining Control
We gain control by making conditions which affect the system
either controllable or observable by the test. We make
test conditions of them.

Sometimes the conditions are already available and the test framework hasn’t taken advantage. In those cases it is a matter of rolling up our sleeves and getting to work.
Sometimes we lose control because of poor test code design. I am not going to go into a list here, because so many people have done a splendid job of covering this territory.
But the most powerful, the most effective way to convert conditions to test conditions is to change the product code. The product must be designed to offer control. The product must be built to be testable.
Control Example: Making Unavailable Conditions Available
I am going to shift all the way to the unit test level because it really does start there.
Consider the following code:
public void PurgeItems(ItemSet items)
{
foreach(Item i in items)
{
if(i.CreateDate < DateTime.Now().AddDays(PURGE_OFFSET))
{
if(!Purge(i))
{
throw new ItemNotPurgedException(i);
}
}
}
}
The conditions that affect the input object, items, are the current system date, as well as a set of hidden conditions behind whatever happens in Purge(). The test conditions are just the contents of the obect items. Any test method is unable to control exactly what time PurgeItems believes it is comparing the i.CreateDate against. It is also unable to check PurgeItems’ behavior when Purge() returns something other than true. It is also unable to check PurgeItems’ behavior were Purge() to likewise throw.
For example, what if PurgeItems() is supposed to purge only down to hour level granularity? How can the test code setup that condition? What if there are special cases of failure in Purge() that PurgeItems ought to handle, maybe skip and move to the next? No test method could check for that.
Consider this change in design:
public void PurgeItems(ItemSet items, IPolicyCheck policy, IItemManager itemManager)
{
foreach(Item i in items)
{
if(policy.GetCurrentTime().AddDays(PURGE_OFFSET))
{
if(!itemManager.Purge(i))
{
throw new ItemNotPurgedException(i);
}
}
}
}
The above implementation turns the current time, and the behavior of Purge() into test conditions. The test code can implement mocks of IPolicyCheck and IItemManager and implement whatever behavior they want to cover for PurgeItems.
Careful observation should reveal I didn’t fix any of the bugs mentioned above. I left it that way to demonstrate that there is still a point to doing the test. Were someone to write a unit test that checks for sub-hour precision, or cause Purge to throw various exceptions the bugs above would be exposed.
While we are at it, let’s break the problem apart even more
Notice how the coverage for PurgeItems() includes checking the item CreateDate relative to different values for current time. With the above refactor, that coverage is possible in unit tests rather than moving to end-to-end tests.
But what if there are other code paths that need to check if an item has expired? The same matrix of CreateDate and date values have to be checked on those code paths as well.
However, if the code is changed as follows so that the logic for checking if an item is expired lies within a method inside IPolicyCheck, we have a huge impact on the test risk:
public void PurgeItems(ItemSet items, IPolicyCheck policy, IItemManager itemManager)
{
foreach(Item i in items)
{
if(policy.ItemExpired(i))
{
if(!itemManager.Purge(i))
{
throw new ItemNotPurgedException(i);
}
}
}
}
This simplifies the behavior of PurgeItems() enormously. It doesn’t have to implement expiration policy at all. It only has three conditions of concern for ItemExpired, whether it returns TRUE, FALSE or throws an exception.
The testing for expiration behavior around settings on an item and date time can be isolated to the implementation of ItemExpired(). It also allows us to extend or change ItemExpired behavior if we need to, and we only touch one piece of code to do it.
This final refactor substantially changes the testing risk around everything that must deal with item expiration to make a decision. In the original version of the code, current time was a condition that could not be controlled. The behavior of PurgeItems() would be flaky under test, but so would all functions that needed to make a decision based on item expiration. By introducing an interface that moves the expiration check under test control, we have the chance to test with flaky behavior removed. By moving the actual policy check to that interface, we have the ability to remove flake across a larger surface area.
This means that even though to an end-to-end test its relationship to the product code remains the same, time of day is still a condition the test procedure will not be able to control, bad behavior around that condition is easier to check at the lower level. The likelihood of a flaky bug is reduced. If such a bug did slip by the lower level checks it would still manifest as flake to the end-to-end test, but it is less likely to get that far unnoticed with the lower level checks able to control that condition.
Unit Level Design Changes Accrue and Ripple Up
I started the discussion of gaining control via design change from unit tests because it is the most effecive, most powerful way to remove flake from a system. With some exceptions (IO being the main one), if one cannot remove flaky behavior from a unit test then the code under test is designed improperly.
But beyond enabling tests, and what most proponents of unit testing will say is that they force a design that is more stable, more extensible, more modular and easier to change later. We create loosely coupled objects that are tied together by interfaces and contracts rather than being tightly coupled dependencies.
From a testing perspective, this means we are able to replace, wrap, or extend the system for sake of testing.
In the PurgeItems example above, IItemManager is used to replace the call to Purge() for sake of running a check against PurgeItems. If we keep this pattern going of providing interfaces between components, we can replace, wrap, or extend with larger and larger systems.
We could, for example, replace an entire cloud based storage system with something running on a local file store, in order to facilitate longer running tests that do not need to connect to the cloud, introducing delays, noise, live accounts, and higher costs. We will not be testing a real system, but if the components are designed in a way that is loosely coupled we can exercise a lot of functionality under far more control.
And control is how we reduce, and if we can eliminate, flake during testing. Control also opens up coverage.
Think of test conditions as data domains, or state domains. In our PurgeIems above, the “DateTime.Now()…” expression represents an entire testing domain around time as it relates to processing data purges. Without that condition under test control, without it being a test condition, the problem is impractical to test. Once under test control the number of potential test cases expands enormously. Coverage grows.
So gaining control is a plus. A win. We want more control. But we cannot rely on our control, because testing is very much about learning something we did not expect, anticipate or know. We have to couple strategies which help us look for things we know about (control) with strategies that broaden our ability to catch what we do not know about (surrender).
Let’s Take a Moment to Talk About Run it Again
The most common solution people use to deal with flaky test results is to run the test again. Repeat the test procedure, and see if the results happen a second time.
Many people declare victory, flake tackled and defeated if a second execution yields results that match expectations.
Are they right?
It depends if they are a developer checking if their newest changes broke the code or not. —————————————————-
If they are, then what they are doing is managing the conditions the test procedure does not control by checking probability. If the result was caused by a recent change, one the developer might have just introduced to the code, then there is a very low probability that it would hit the first execution of a check against the code and NOT hit the second excution. Even if it were a flaky behavior, there is a low probability that the first execution of the check would hit it at all.
This means that any kind of flaky behavior observed during execution of a check is a higher probability indicator of a problem that was in the code long prior to the change the developer just made. I describe the math supporting this idea in a different article.
Re-run is a valid strategy if you are a developer asking the question “Did I just break something?”
This is very different than learning about product behavior.
If someone is trying to learn about product behavior, then a flaky signal is a very important piece of information. The flaky signal is an indication that some condition not under test procedure control is changing in a way that produces unexpected or surprising results.
Something is not right. Either there is a problem in the test procedure, or there is a problem in the product. Either way, the information means we have something to investigate, and something we should probably change.
Surrendering control for the win
When we model testing from this idea of there being conditions the test can control and observe versus not, we can start to recognize why we want to test in different ways. While a good deal of the time we are checking for specific, anticipated problems, sometimes we are intentionally looking for flaky behavior in the product. One way to do that is to increase the amount of conditions outside of test procedure control.
Consider the following example - testing a formula which does addition in Microsoft Excel.
Condition scope at different levels of control
Let’s imagine a unit test in Excel while checks if 1+1==2. A trivial test. If we diagram the conditions under control of the test procedure in a unit test, it would look like this:
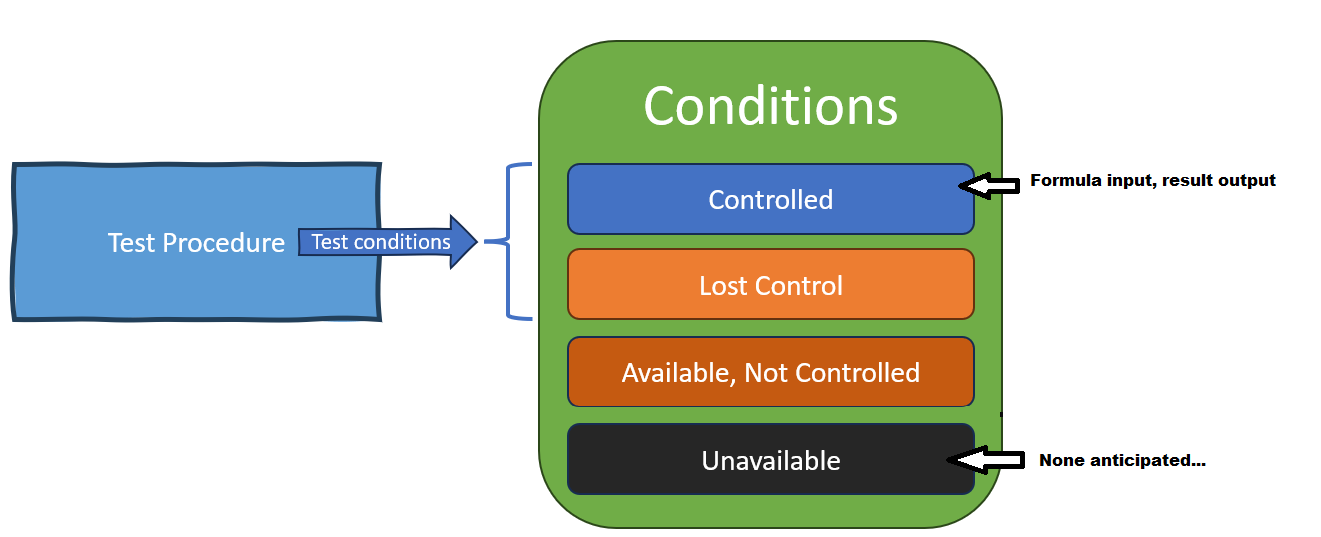 Every condition we can imagine that ought to affect the
behavior of the system is under direct control of the
test procedure. By isolating the test to the unit level,
we have removed all other conditions that might
affect system behavior. The test procedure is checking just one
thing, which is how the system state changes as the
test condition is changed.
Every condition we can imagine that ought to affect the
behavior of the system is under direct control of the
test procedure. By isolating the test to the unit level,
we have removed all other conditions that might
affect system behavior. The test procedure is checking just one
thing, which is how the system state changes as the
test condition is changed.
 If we do the same test at the UI level, by placing the
formula “=1+1” in a cell and then checking that cell to
see if it contains the value “2” for a result, the map
of conditions changes dramatically. Ignoring lost control
and available but not utilized, the biggest change happens
in the unavailable conditions. When we check the same
use case via the UI, Excel will execute thousands of code
paths on the way to delivering those results. Each of
those code paths introduces multiple conditions that can
affect the outcome of the check. This end to end check,
while attempting to check just one thing, is giving
us coverage of thousands of code paths. It does that
by surrendering control.
If we do the same test at the UI level, by placing the
formula “=1+1” in a cell and then checking that cell to
see if it contains the value “2” for a result, the map
of conditions changes dramatically. Ignoring lost control
and available but not utilized, the biggest change happens
in the unavailable conditions. When we check the same
use case via the UI, Excel will execute thousands of code
paths on the way to delivering those results. Each of
those code paths introduces multiple conditions that can
affect the outcome of the check. This end to end check,
while attempting to check just one thing, is giving
us coverage of thousands of code paths. It does that
by surrendering control.
If Excel has any flaky behavior of its own, it isn’t going to demonstrate that in our unit test. It is far more like to go flaky in the end to end test.
Embracing the unknown problem
It is common, generally the norm, that there are conditions in a system which we do not know about or understand. Sometimes the condition is completely unknown, we have no idea it existed. Sometimes it is known, but we do not understand the affect is has on system state. Sometimes a set of conditions are known, but interact in a way we do not anticipate.
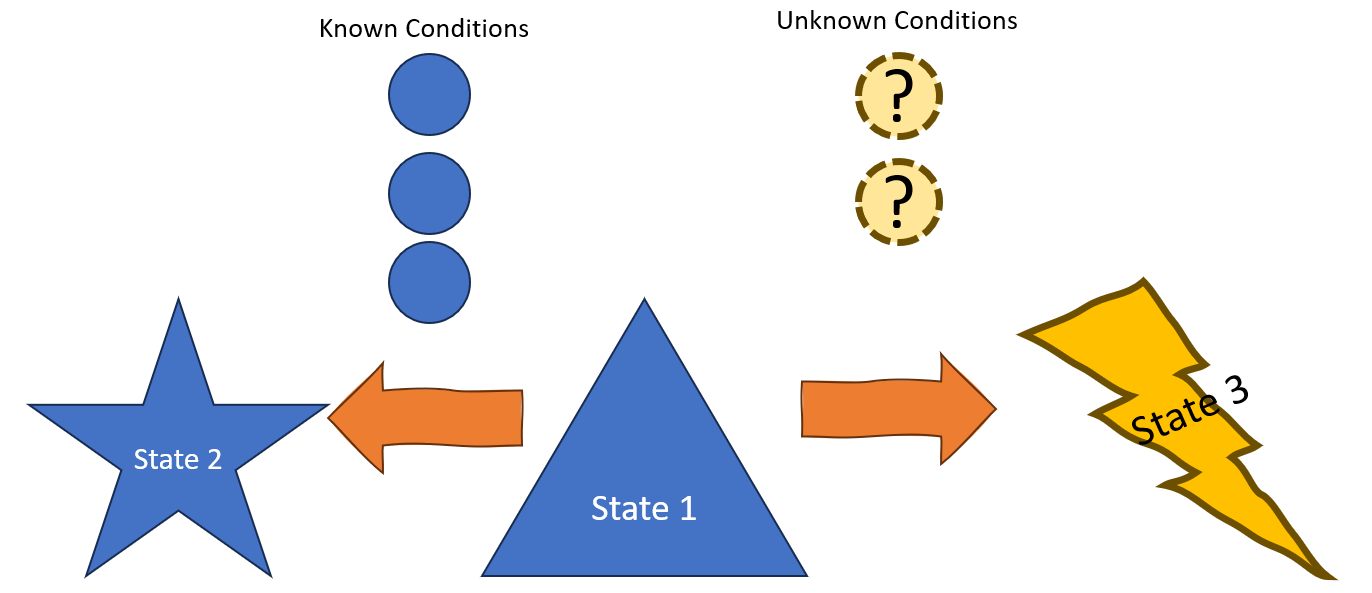
One of the key challenges, and goals of testing is to surface problems that arise from unknown and misunderstood conditions. We do that through various approaches that increase the odds of conditions changing.
Unknown Problem Example
Let’s go back to that earlier example of the timer job intersecting with creating objects.
Let’s pretend the code for each does the following:
CREATE ITEM
1. write item default row to store
2. check item policy service for metadata
3. write item metadata to row
PURGEITEM TIMER JOB
1. query for all items in system
2. for each item, if createdate < expiry, purge
Let’s pretend that when “write item to default row” happens, the item is initialized with MIN_DATE, whatever that value is in the data store. Le’s pretend that neither of these behaviors are atomic or transacted (hey, this is a bug… people make mistakes… or maybe there is a design reason why it cannot be atomic…). The two processes are independent, so if the timer job executes between steps 1 and 3 of CREATE ITEMS, the item will be purged, even though it was newly created.
How do we test for that? We have the following options:
- in some low level test (technically not a unit test because we are engaging IO), use a Humble Object design pattern to allow control sequencing of the steps to see what happens when they mix
- in some test system, increase the frequency of the timer and put object CRUD under workload to increase the probability of this kind of thing happening
- in an end to end system, put object CRUD under workload to incrase probability of this kind of thing happening
- as part of functional checks, use object CRUD for each type of object and check store if it is there
Low level unit test
The method which would reproduce the failure consistently, without flake, is #1. The reason is because utilizing the Humble Object design pattern allows the test procedure to control race conditions by interleaving individual actions in whatever order the test procedure desires.
The dilemma, though, is we have to anticipate exactly this problem to create the test in the first place. We have to worry that the CREATE ITEM functionality and PURGEITEM functionality will interleave their code to create race conditions that change based on subtle, small differences in timing. At the low level, the Humble Object design pattern involves creating the race conditions exactly. If we think of this, well done.
But we tend not to. That is why we have bugs, because the thinking of the problem in time to imagine the test procedure often enough keeps us from introducing the bug in the first place.
End to end tests with multiple executions - i.e. stress and load
We move on to the types of tests which catch things that we do not expect. Alternatives #2 and #3 above have a good chance of catching the bug, but are not guaranteed. The difference between #1 and #2-3 is that the latter methods surrender control. And the reason they do that is because they are not anticipating this specific bug. What they are looking for is written in the description, this kind of thing. We don’t know what bug is there, nor exactly which code paths have which bugs, but we do believe that doing certain things are more likely to fail.
We are increasing probability of finding something unknown, unexpected, and undesired. And we are leaning into that by surrendering control. When we have control, we direct the test conditions toward our intentions. If we manipulate the system to find something we anticipate, we tend to miss anything not directly under that focus. To find everything with control we have to point at each and every thing exactly.
When we surrender control, the range and scope of our focus increases. The app does more things. More conditions change. More importantly, conditions we do not control start changing, even when we do not know they exist.
Consider the end to end test for our CRUD API, and the following result:
Executed ADD_EVENTBOOKING at BookingsGalore.com endpoint, at rate of 100 RPS for 32 hours, and had a 1% rate of bookings not showing up in storage when checked. Examination of logs show those same bookings purged by timer jobs.
The sustained workload test tells us about product flakiness, and in a non-flaky way. But it does not eliminate flake. It is more like it embraces flake. It seeks to describe the nature of the flake, a measurement of the conditions the test does not control by telling us how often those conditions create the unexpected result. The test procedure has not gained any control over the test condition, has not observed it, does not have any access to what the condition is. All it has is a measurement that the test procedure is able to provide with some range of reliability.
One of our typical project constraints is that a 32 hour workload test is not going to be at all acceptable on something like a build validation or deployment pipeline. The run time is too long, the results - being a percentage threshold, require analysis to decide what to make of it.
End to end functional check
Consider now test #4, a single call check of basic functionality. Fast. Simple. Atomic. And in this case, if our workload tests tell us anything predictable, is going to fail 1/100 times.
The problem is, we don’t know that when we craft the test. We won’t see the failure to know there is any flake at all until the first time the check hits it, and then it won’t hit it again until many executions later.
We cannot really know what we are looking at until either waiting, or changing our functional test into a load test. But that is for solving a different problem.
Eliminating the flake from the end to end system
Let’s stick with our timer job/CRUD operation problem. Let’s imagine we anticipate the possibility that background processes of any sort might interfere with various checks. We don’t necessarily KNOW the bug we are talking about exists, we just want checks we can rely on.
We address this problem by turning off all background processes. The timer jobs are disabled, purging expired items being one of those disabled operations.
I did not make this up. When I worked on SharePoint, one of the common configuration steps on all of the automated suites was to disable all timer jobs. We had configurations where we would turn the timer jobs on if we wanted, but for most tests, in order to keep the results more consistent and less confusing, any background process was turned off.
We were gaining control of a condition by eliminating it. It worked. Our test results stabilized.
The other effect of doing this is it means we were not testing for the case where timer jobs interfered with other system functions. We were losing test coverage in the name of gaining control.
We made up for it by having other testing where everything in the system was running. We did this because we knew that when we were looking for precise controlled test results with a reliable, consistent signal we were missing important bugs in the system.
Getting Control Over this Article
Understanding, dealing with, and even exploiting flaky results during testing is far easier when we see it as a matter of controlling conditions. Ultimately what we want to do is find and remove product flake so that we and our customers do not have to deal with it when we use our products and services.
When we recognize flake as a result conditions the test procedure does and does not control, we can use that to find the product flake more effectively, manage flake that prevents us from getting a reliable product signal, and maximize our strategies to shine a lot on product flakiness that put the business and customer interests at risk.