Developer As Tester Advantages I Never Had As A Tester
When you are the developer, you can change the testing problem
I know the metaphor is weird, but I couldn’t think of anything else, and I kind of like drawing penguins.
I have a long history as a tester, and one of the things I take very seriously is coming up with testing ideas, methods, and strategies. I see testing as largely a game of probabilities and odds. I am trying to increase the chances I will find a problem that to this point has gone unnoticed.
When I do this, I am not thinking very much about the layers or stacks of the product. I think instead of the possibility of failures or mistakes or undesirable outcomes intrinsic to the problem we are trying to solve with the product. These are problems that tend to exist no matter how the product is implemented.
I add to that issues and risks that come about from the design and implementation choices. But even driven by design choices, I still think of those problems as inherent to the whole space.
After thinking of those problems, I imagine how to test them, and this is where I experience a big difference as a tester versus someone who writes and fixes the code under test. As a tester, I was mostly subject to whatever designs the team had agreed upon, which I could offer feedback into, but I had no control over them. Whatever come out, I had to take that in what form it was and test wherever it was possible to do so. Often this meant doing large and complex permutations on data and sequences of actions at the most abstract layer, end-to-end in the UI on a fully integrated system. I found a lot of bugs this way, but coverage of the space I was trying to test was slow and difficult and investigation complicated.
As the person who writes and fixes the code, I can change the code to change the way I test it. Even better, if I come into writing the code anticipating the tests, I can design the code to make it possible to test the problem at the lowest level; in the unit.
An example: a web-ui based data schema builder/generator application
Let’s imagine we have a web-UI based drag and drop data schema editor and content generator. We build data schemas graphically, and then ask the tool to generate examples of that data. (This image is pretend - complete vaporware. I know it seems similar to a project I write about in other articles, but so far none of that has any UI ambitions).
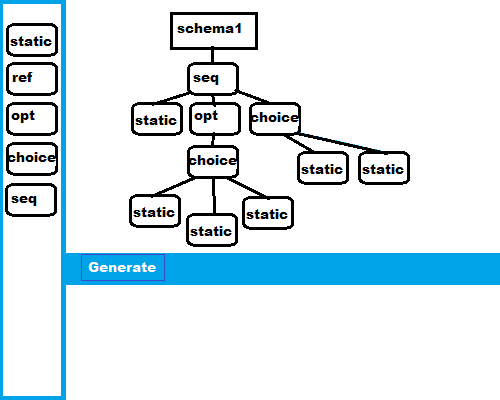
During test analysis, I come up with lists of hundreds of test ideas. These include different configurations of types of objects in the data schema, ways of dealing with the randomness of the example generation, gestures in the UI for building and modifying the schema, saving to storage, retrieving from storage, combining schema together with references, deeply nested schema references, loops that will and will not terminate, and on and on.
As the tester, I give the feedback I have to give, and take what I am offered
Let’s pretend that as a team we are building out the acceptance suite, and I offer an analysis of the different kinds of object relationships that can exist in a data schema. I present a test strategy with samples of all the different types of schema I want to use in the testing.
I raise an issue:
Schema Permutation Testing: The product presents only one way to generate schema and feed it to the system, and that is through the UI. This will make testing slow, automation of any tests error prone. Advise we present testability hooks to allow schema creation programmatically to facilitate faster testing.
The issue is deferred as “Won’t Fix”, the argument being that customers are using the UI only, so exposing an API for creating schema objects is not a priority. Test risks are acknowledged, but development is told to proceed without working on the testability hooks.
This means that to test this suite of different data shapes I am going to have to pump it through the UI. Either I do that unaided by tools, clicking and dragging and typing away one object at a time, or I write a UI targeting automation suite, and spend the rest of the schedule trying to tame it into stable behavior. By the time I start reporting bugs from testing this behemoth, the product code is all a tangle because nobody has looked at this level of data complexity until long after the code was written. The developer is having a dreadful time understanding how to fix each bug without breaking everything else.
As the developer, I try to think how I can make the testing easier
Rewind that story, only this time I am the developer, and the tester, and I have the test analysis and suite of cases in front of me.
I really do not want to write any UI automation. If I can get away with zero UI automation I would.
I really do not want all the parts and pieces of the system contributing to the complexity of the problem when I am debugging.
I would really like to know, as I am writing the code, if all of these different shapes in the data are handled as we want them to be. I want to know that concern of this problem is handled before integration with other code.
I really want to be able to add a new case to this set of possible data shapes easily, see what the product does quickly, and then fix whatever problems arise while also easily and quickly seeing if that broken anything else.
I cannot do that if I have to test at the UI. I cannot even do that if I have to test using a public product API, such as a REST API. I want to do that in the unit test level where I can check one behavior at a time, stripped of all dependencies and other things going on.
This has a lot of impact in the code, and most of it superior product design that I might have naively tossed in a rush to meet a schedule. I talk about some of these issues in other articles, such as refactoring that changes as we change product designs, removing flake by refactoring the app, how we can establish test control through refactoring, how skipping your unit tests can lead to problems later, and even how you need to think of both big and small picture problems for your unit tests.
Another example, making the end to end testing easier
When I was in Office, one of the things I worked on was AI-driven automation. Rather than writing the automated scripts ourselves, an AI agent would learn how to use the Office client by randomly manipulating its controls and observing how that changed UI state.
The AI agents were using the Microsoft Accessibility API to navigate, observe, and control the applications. This is the same API that vendors use to create accessibility tools for Windows applications.
One of the difficulties that came up was that many of the controls in the Office UI did not expose the “AutomationID” property. This a property that uniquely identifies a control within an application, allowing automation tools a robust and reliable way to find that control later. When that id is not present, the tools have to fallback on other properties, such as element name, classname, or location within the tree of UI controls. The challenge with those mechanisms is they were not unique. For example, many of the Office UI controls have a sub menu called “More Options…”, and without a unique AutomationId, the AI controlled agents had no way of knowing which one they were asking for later.
When you have to ask someone to do something…
As a tester, the best I would have been able to do was politely ask the team that owned these controls (on the Shared Code team in Office, all the UI controls came through them) to put AutomationId on all of the controls didn’t have them. I would have had a good case for it beyond just my AI-based testing work, as it would improve the Accessibility scenario.
And the response would have been “sounds like a good idea, but our schedule is booked solid for the next three quarters…”
I know that is the response I would have got, because that is the response I initially got when I wanted to see if I could get them to do the work.
When you can do it yourself
For some reason, the string change from “Software Development Engineer in Test” to “Software Engineer” is all that it took to ask “How about if I changed it myself” and have the answer be “Okay, so long as you work with the lead on that, because the code stack is really complicated. As you work with them, it is fine.” People who say job titles are meaningless aren’t really paying attention to the social power of labels.
And that is what I did. I talked to the person who owned all of the UI control code in Office, had him explain to me how that code worked (this is the story of over 30 years of source code drifting across multiple OS UI paradigms and platforms, constantly writing new wrappers around old code to keep it working and new stuff around new code to take advantae of new behaviors. It is a crazy complex pile multiple layers of indirect C++ and XML and build-time manifest generating code.). It was harder than I wanted it to be, but I managed to get a lot of the controls emitting an AutomationId, and was able to track an improvement in our AI agent coverage rates as a result.
In some ways I prefer the change
I miss a lot of things about being a dedicated test engineer.
But I also find that a lot of the time when developers and testers were separate disciplines that I wanted a lot of things to change to make the product easier to test, make it more stable, make it easier to investigate and monitor and control. I found that even when we made our case for those things, they mostly didn’t happen.
My observation is that pushing a substantial testing burden on the developers forces some of the testing to be better. This is not about tester talent, or intelligence. This is about what the person responsible for testing is able to control. When testing is a key concern and responsibility of the developer, they start to look at the product as a testing problem to solve, and then look for ways to make that testing easier.
The effect this should have is that if there are people who focus mostly on testing, they can focus on more meaningful work. Rather than being forced to take a slow slog through tedious problems that should have been done in much more efficient, effective ways, they will move on to problems that are much trickier, more deserving of focused long hours investigating hard problems.